背景 最近在公司收到了一条告警,K8S 集群中的 GPU 的节点一台接一台的变成了 NotReady 状态了。过了半个小时,业务找我说他们的服务起不来了,同时服务的所有的实例全都异常了。因为我们线上没有关闭 controller manager Node 异常的驱逐,如果业务代码会把宿主机节点跑死,节点上的异常业务就会触发迁移,迁移完接着把下一台节点跑死。如同葫芦娃救爷爷一般,全军覆没。最后 GPU 节点全部跪了。
复现 业务侧复现 业务侧给了一个jar包,pod 配置内存 limit 40g,宿主机62g内存。则会出现异常,宿主机节点会被跑死。
将 Pod 的内存 limit 改为 20g,Pod 则会运行一段时间后达到 cgroup 的限制大小,触发OOM。
模拟复现 如过你也想在自己的集群里模拟复现类似的场景可以使用如下方式。
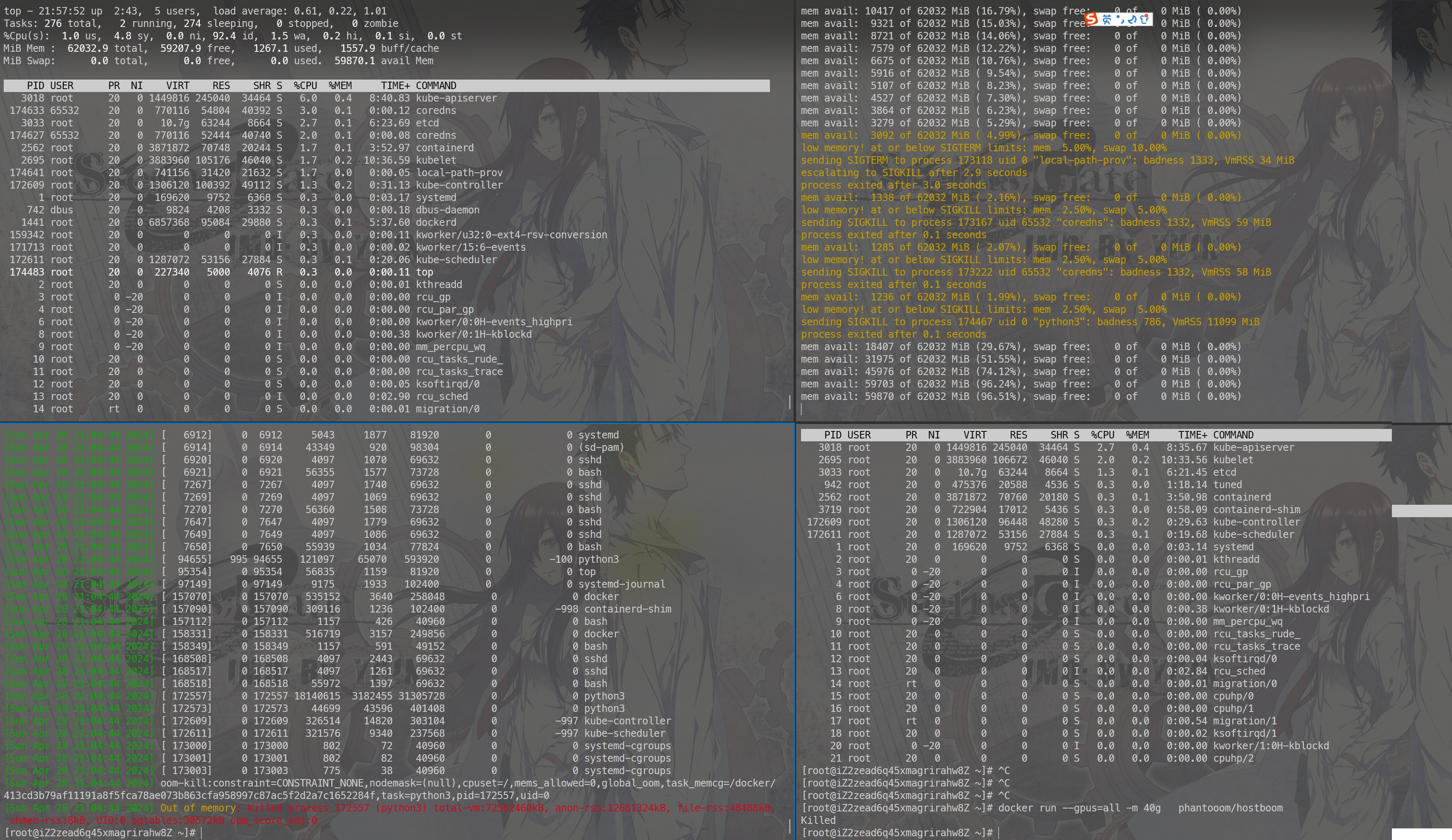
下面尝试用 docker 复现需要在阿里云开一台 GPU 实例 ecs.gn6i-c16g1.4xlarge 16c64g 1*T4 GPU这个规格,大体上20块钱一个小时。驱动选择自动安装就好。都勾上。系统选择 alinux3.2
1 2 3 4 5 6 7 8 9 10 11 12 curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo sudo yum install -y nvidia-container-toolkit sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin sudo systemctl start docker [ $(uname -m) = x86_64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.22.0/kind-linux-amd64 chmod +x ./kind sudo mv ./kind /usr/local/bin/kind kind create cluster --name k1 sudo docker run --gpus=all -m 40g -it phantooom/hostboom-tiny
问题排查 节点已经关闭swap了。
为什么 Pod limit 40g 节点会处于半死不活的状态?
为什么同时 Pod 没有被 OOM 掉?
为什么 Pod limit 20g 则 Pod 会被正常 OOM 掉?
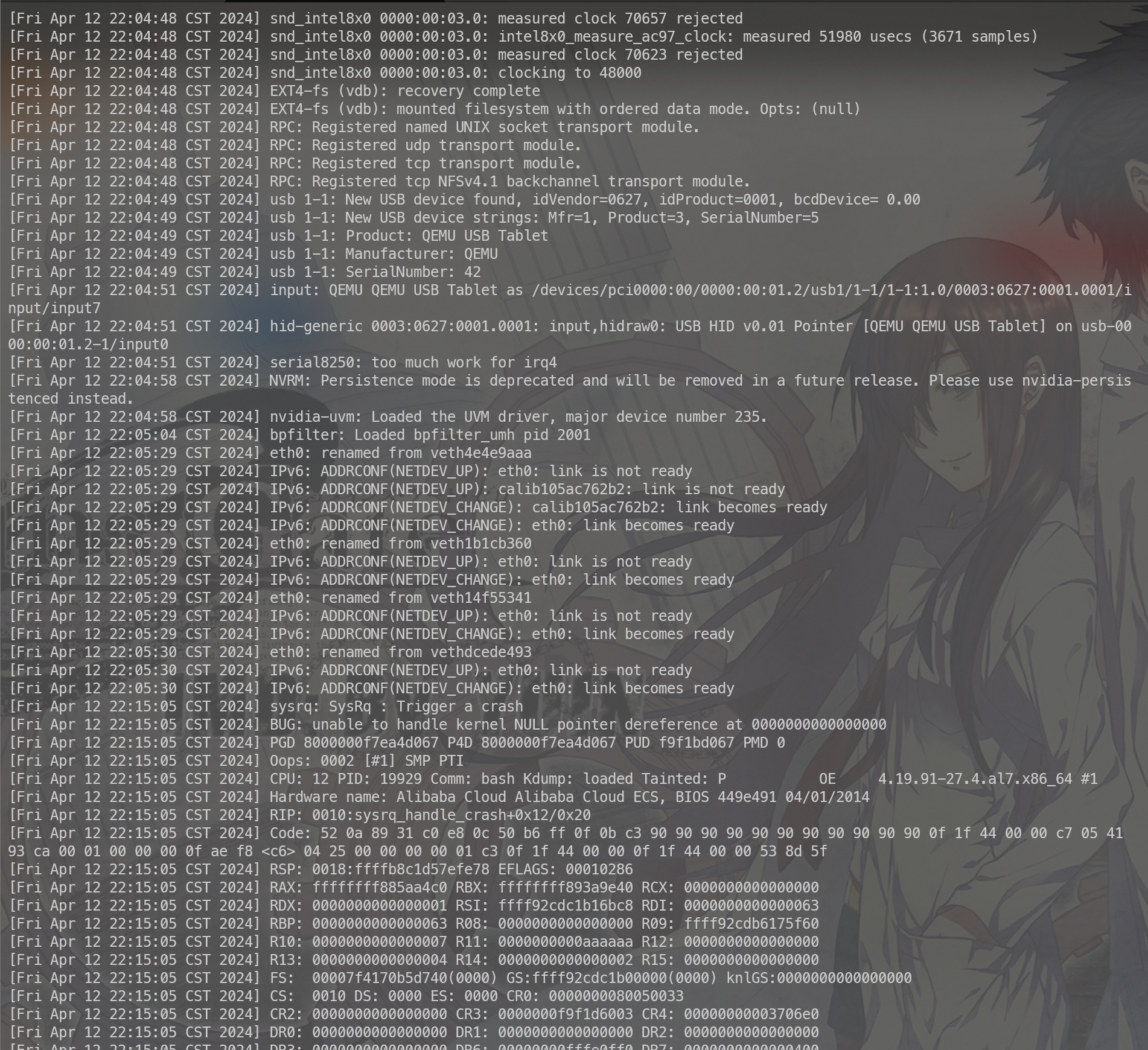
运行异常代码,一会你就会发现节点变成 NotReady(K8S节点状态) 了。然后机器的负载变得非常的诡异。不管是ssh 还是vnc。执行任何命令都变的非常的慢,可能十几秒钟可以输入一个字符。
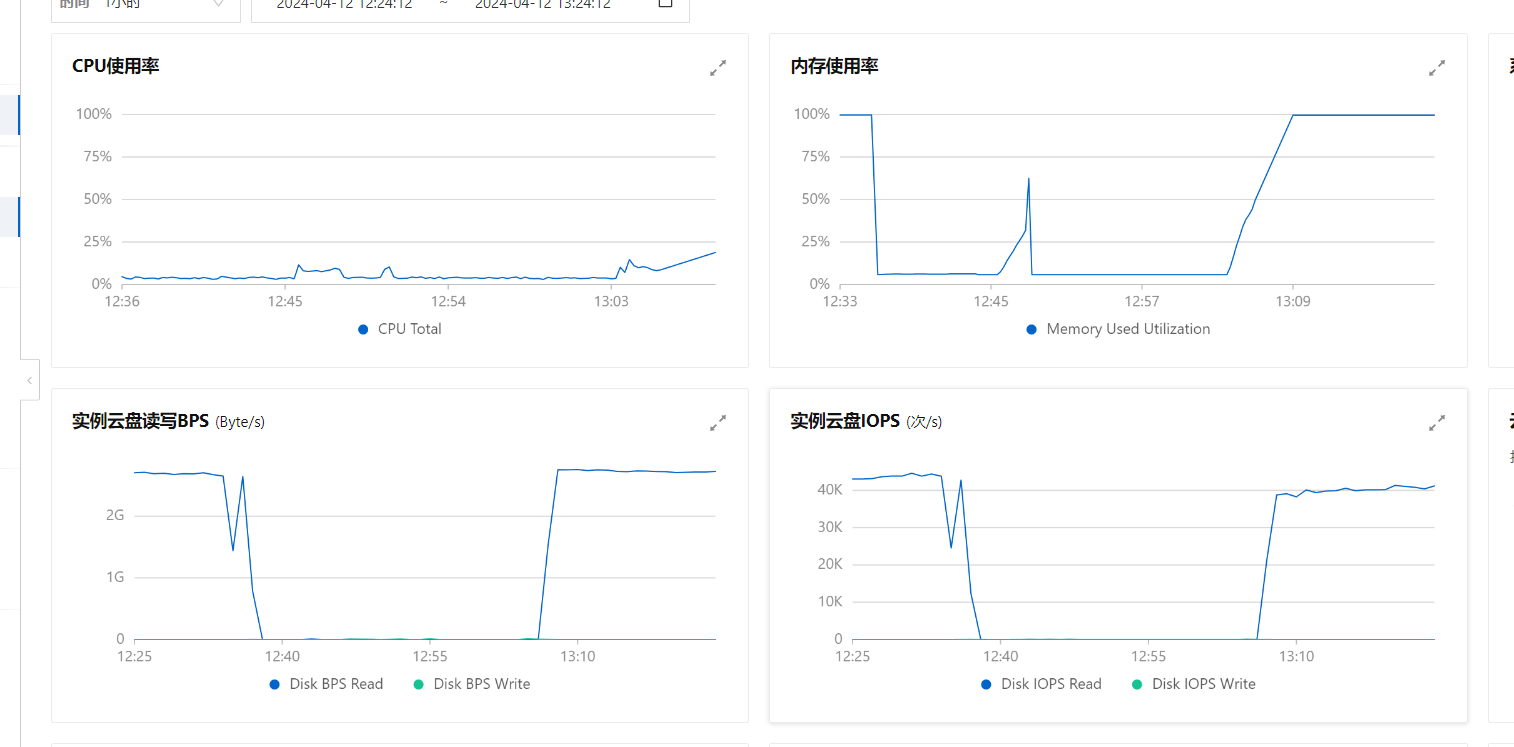
资源占用大体上是这个样子的。
打满的IO 磁盘读 IOPS 4w的样子依然是打满状态,我们观察下到底是谁占了,如下图所示:
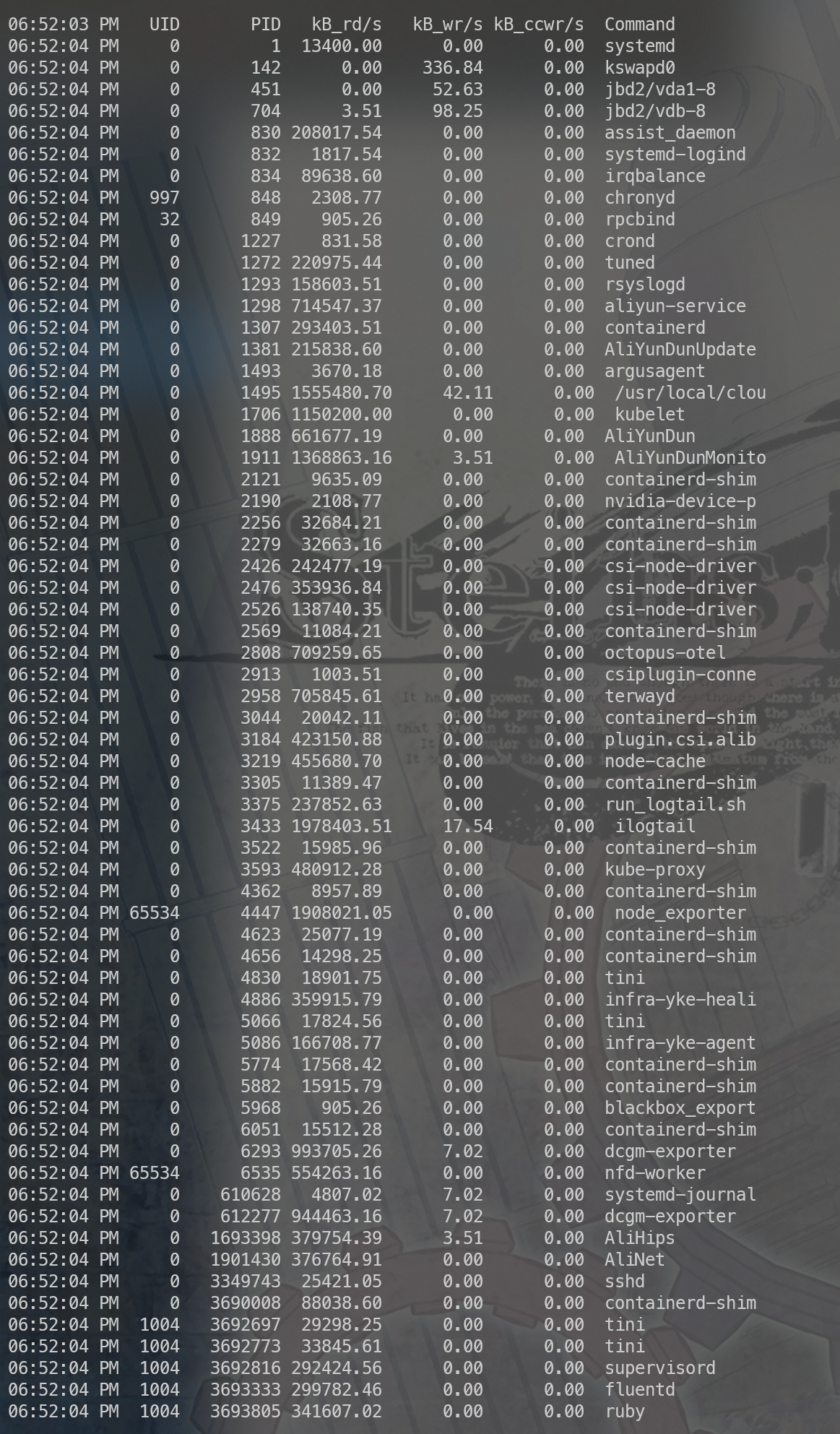
几乎所有程序都在疯狂的进行读操作,这是为什么?
被刷空的cache
观察到 IO 打到非常高。同时看了一下 top 如上图所示,这个大概猜到是cache全部被刷出去了造成。程序要运行,如果依赖了动态库则这部分需要加载到内存当中,这部分内容是用到的时候如果不存在则触发缺页中断从磁盘加载,平时也不会也不会释放,但是如果内存非常紧张的时候则这部分内存是允许释放的,如果程序再次执行的时候需要到动态库里面的代码则重新触发缺页中断,从磁盘读取。所以我们猜测大体上是内存紧张,动态库分配的内存被释放了。
进一步验证
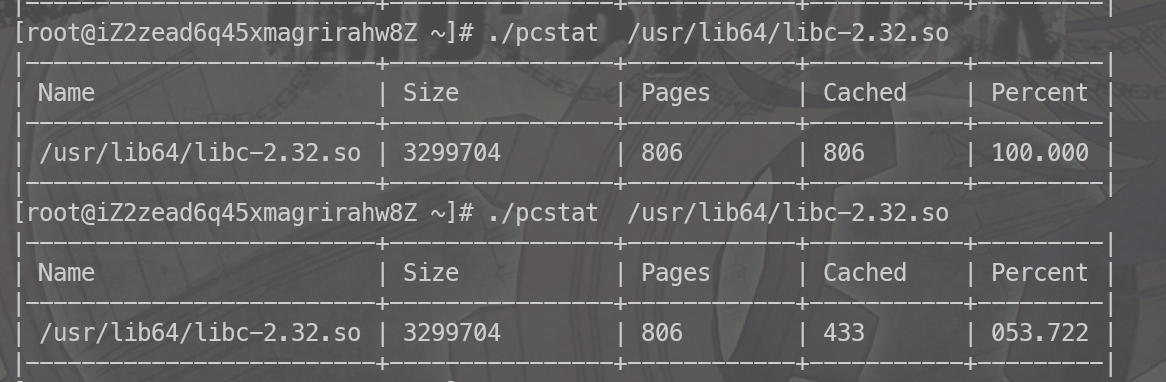
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 +-------------------------------------------------------------------------------+----------------+------------+-----------+---------+ | Name | Size (bytes) | Pages | Cached | Percent | |-------------------------------------------------------------------------------+----------------+------------+-----------+---------| | /usr/ local/cloudmonitor/bin/argusagent | 114843023 | 28038 | 1069 | 003 .813 | | /usr/ bin/kubelet | 188908296 | 46121 | 820 | 001 .778 | | /usr/ bin/containerd-shim-runc-v2 | 10158080 | 2480 | 629 | 025 .363 | | /root/ hcache | 2542252 | 621 | 540 | 086.957 | | /usr/ local/share/aliyun-assist/2.2 .3 .579 /aliyun-service | 32559921 | 7950 | 322 | 004 .050 | | /usr/ lib64/libc-2.32 .so | 3299704 | 806 | 311 | 038.586 | | /usr/ bin/containerd | 53171440 | 12982 | 274 | 002 .111 | | /usr/ local/share/assist-daemon/assist_daemon | 3819656 | 933 | 271 | 029.046 | | /usr/ local/aegis/aegis_client/aegis_11_37/libModuleMetadata.so | 2996336 | 732 | 269 | 036 .749 | | /usr/ lib64/libsystemd.so .0 .23 .0 | 1398376 | 342 | 165 | 048.246 | | /usr/ local/aegis/aegis_client/aegis_11_37/libgrpc.so .10 | 4040312 | 987 | 80 | 008.105 | | /usr/ lib64/libpython3.6m.so .1 .0 | 3164008 | 773 | 76 | 009.832 | | /usr/ local/aegis/aegis_client/aegis_11_37/AliYunDun | 3174360 | 775 | 59 | 007 .613 | | /usr/ local/aegis/aegis_client/aegis_11_37/libaegisProcMng.so | 441632 | 108 | 53 | 049.074 | | /usr/ lib64/libstdc++.so .6 .0 .28 | 2034504 | 497 | 48 | 009.658 | | /usr/ lib64/libtinfo.so .6 .1 | 187488 | 46 | 46 | 100.000 | | /usr/ lib/systemd/libsystemd-shared-239. so | 2767336 | 676 | 32 | 004 .734 | | /usr/ local/aegis/aegis_client/aegis_11_37/libaegisMonitor.so | 348504 | 86 | 27 | 031 .395 | | /usr/ lib64/ld-2.32 .so | 268904 | 66 | 19 | 028.788 | | /usr/ local/aegis/aegis_client/aegis_11_37/libgpr.so .10 | 73440 | 18 | 16 | 088.889 | | /var/ db/nscd/passwd | 217032 | 53 | 16 | 030 .189 | | /usr/ local/aegis/aegis_client/aegis_11_37/libaegisFileWatch.so | 387464 | 95 | 16 | 016 .842 | | /usr/ lib64/libpthread-2.32 .so | 304440 | 75 | 16 | 021 .333 | | /usr/ local/aegis/aegis_client/aegis_11_37/libaegisNetWork.so | 583920 | 143 | 15 | 010 .490 | | /var/ db/nscd/group | 217032 | 53 | 15 | 028.302 | | /usr/ local/aegis/aegis_client/aegis_11_37/libaqsUtil.so .1 | 573840 | 141 | 15 | 010 .638 | | /usr/ local/aegis/aegis_client/aegis_11_37/libaegisIpc.so | 215080 | 53 | 12 | 022 .642 | | /usr/ lib64/libglib-2.0 .so .0 .6800 .4 | 1300472 | 318 | 10 | 003 .145 | | /usr/ local/aegis/aegis_update/AliYunDunUpdate | 3724520 | 910 | 9 | 000 .989 | | /usr/ local/aegis/aegis_client/aegis_11_37/libModuleCommon.so | 603664 | 148 | 7 | 004 .730 | | /etc/ csi-tool/csiplugin-connector | 3385062 | 827 | 2 | 000 .242 | | /usr/ local/aegis/aegis_client/aegis_11_37/libaqsHttp.so .1 | 41528 | 11 | 2 | 018.182 | | /usr/ local/aegis/aegis_client/aegis_11_37/libaegisCommon.so .1 | 202288 | 50 | 2 | 004 .000 | | /usr/ lib64/libdbus-1. so.3 .19 .7 | 359480 | 88 | 2 | 002 .273 | | /usr/ local/aegis/aegis_client/aegis_11_37/libFileQuara.so | 512496 | 126 | 2 | 001 .587 | | /usr/ sbin/rngd | 123872 | 31 | 2 | 006 .452 | | /usr/ lib64/libev.so .4 .0 .0 | 71416 | 18 | 2 | 011 .111 | | /usr/ sbin/atd | 37344 | 10 | 2 | 020 .000 | | /usr/ lib64/rsyslog/imjournal.so | 38312 | 10 | 2 | 020 .000 | | /usr/ lib64/libgio-2.0 .so .0 .6800 .4 | 2053336 | 502 | 2 | 000 .398 | | /usr/ sbin/chronyd | 371672 | 91 | 2 | 002 .198 | | /usr/ sbin/iprinit | 153184 | 38 | 2 | 005 .263 | | /usr/ sbin/iprupdate | 153264 | 38 | 2 | 005 .263 | | /usr/ bin/rpcbind | 71128 | 18 | 2 | 011 .111 | | /usr/ sbin/iprdump | 153616 | 38 | 2 | 005 .263 | | /usr/ lib64/libm-2.32 .so | 1921824 | 470 | 1 | 000 .213 | | /usr/ sbin/sshd | 906736 | 222 | 1 | 000 .450 | | /run/ systemd/journal/kernel-seqnum | 8 | 1 | 1 | 100.000 | | /usr/ local/aegis/aegis_client/aegis_11_37/libaqsNetWork.so .1 | 32552 | 8 | 1 | 012 .500 | | /usr/ lib64/libblkid.so .1 .1 .0 | 347608 | 85 | 0 | 000 .000 | | /usr/ lib64/libresolv-2.32 .so | 130104 | 32 | 0 | 000 .000 | | /usr/ lib64/libkeyutils.so .1 .6 | 24344 | 6 | 0 | 000 .000 | | /usr/ lib64/libkrb5support.so .0 .1 | 71408 | 18 | 0 | 000 .000 | | /usr/ lib64/libhogweed.so .4 .5 | 206008 | 51 | 0 | 000 .000 | | /usr/ lib64/libgmp.so .10 .4 .0 | 687248 | 168 | 0 | 000 .000 | | /usr/ lib64/libgnutls.so .30 .28 .2 | 2067656 | 505 | 0 | 000 .000 | | /usr/ lib64/libnettle.so .6 .5 | 243544 | 60 | 0 | 000 .000 | | /usr/ lib64/libffi.so .6 .0 .2 | 41312 | 11 | 0 | 000 .000 | | /usr/ lib/systemd/systemd-resolved | 470928 | 115 | 0 | 000 .000 | | /usr/ lib64/libp11-kit.so .0 .3 .0 | 1266728 | 310 | 0 | 000 .000 | | /usr/ lib64/libtasn1.so .6 .5 .5 | 78800 | 20 | 0 | 000 .000 | | /usr/ lib64/libtirpc.so .3 .0 .0 | 201048 | 50 | 0 | 000 .000 | | /usr/ lib/systemd/systemd-logind | 275016 | 68 | 0 | 000 .000 | | /usr/ lib64/libcom_err.so .2 .1 | 24920 | 7 | 0 | 000 .000 | | /usr/ lib64/libbrotlicommon.so .1 .0 .6 | 138912 | 34 | 0 | 000 .000 | | /usr/ lib64/libsasl2.so .3 .0 .0 | 129568 | 32 | 0 | 000 .000 | | /usr/ lib64/libldap-2.4 .so .2 .10 .9 | 341296 | 84 | 0 | 000 .000 | | /usr/ lib64/liblber-2.4 .so .2 .10 .9 | 67104 | 17 | 0 | 000 .000 | | /usr/ lib64/libcrypt.so .1 .1 .0 | 144264 | 36 | 0 | 000 .000 | | /usr/ lib64/libpsl.so .5 .3 .1 | 78832 | 20 | 0 | 000 .000 | | /usr/ lib64/libgssapi_krb5.so .2 .2 | 359936 | 88 | 0 | 000 .000 | | /usr/ lib64/libjansson.so .4 .14 .0 | 67168 | 17 | 0 | 000 .000 | | /usr/ lib64/libbrotlidec.so .1 .0 .6 | 57736 | 15 | 0 | 000 .000 | | /usr/ lib64/libssh.so .4 .8 .7 | 476840 | 117 | 0 | 000 .000 | | /usr/ lib64/libnghttp2.so .14 .17 .0 | 175128 | 43 | 0 | 000 .000 | | /var/ db/nscd/hosts | 217032 | 53 | 0 | 000 .000 | | /usr/ lib64/libk5crypto.so .3 .1 | 100432 | 25 | 0 | 000 .000 | | /usr/ lib64/libnss_sss.so .2 | 50344 | 13 | 0 | 000 .000 | | /usr/ sbin/nscd | 219992 | 54 | 0 | 000 .000 | | /var/ db/nscd/netgroup | 217032 | 53 | 0 | 000 .000 | | /var/ db/nscd/services | 217032 | 53 | 0 | 000 .000 | | /usr/ lib64/libnss_systemd.so .2 | 955680 | 234 | 0 | 000 .000 | | /usr/ lib64/libnss_myhostname.so .2 | 727808 | 178 | 0 | 000 .000 | | /usr/ lib64/libnss_dns-2.32 .so | 39896 | 10 | 0 | 000 .000 | | /usr/ lib/locale/locale-archive | 223542144 | 54576 | 0 | 000 .000 | | /usr/ bin/dbus-daemon | 253328 | 62 | 0 | 000 .000 | | /usr/ lib64/libexpat.so .1 .6 .7 | 190784 | 47 | 0 | 000 .000 | | /usr/ lib64/libkrb5.so .3 .3 | 975024 | 239 | 0 | 000 .000 | | /usr/ lib/systemd/systemd-udevd | 434032 | 106 | 0 | 000 .000 | | /usr/ lib/modules/5.10 .134 -16.1 .al8 .x86_64 /modules.alias .bin | 696359 | 171 | 0 | 000 .000 | | /usr/ lib64/libgmodule-2.0 .so .0 .6800 .4 | 20088 | 5 | 0 | 000 .000 | | /usr/ sbin/NetworkManager | 3597064 | 879 | 0 | 000 .000 | | /usr/ lib64/NetworkManager /1.40 .16 -4.0 .1 .al8 /libnm-device-plugin-team.so | 53728 | 14 | 0 | 000 .000 | | /usr/ lib/modules/5.10 .134 -16.1 .al8 .x86_64 /modules.builtin .bin | 11735 | 3 | 0 | 000 .000 | | /usr/ lib64/gconv/gconv-modules.cache | 26998 | 7 | 0 | 000 .000 | | /usr/ lib64/NetworkManager /1.40 .16 -4.0 .1 .al8 /libnm-settings-plugin-ifcfg-rh.so | 314560 | 77 | 0 | 000 .000 | | /usr/ lib64/libgobject-2.0 .so .0 .6800 .4 | 376296 | 92 | 0 | 000 .000 | | /usr/ lib/modules/5.10 .134 -16.1 .al8 .x86_64 /modules.dep .bin | 256904 | 63 | 0 | 000 .000 | | /usr/ lib64/libndp.so .0 .1 .1 | 33040 | 9 | 0 | 000 .000 | | /usr/ lib64/libpcre.so .1 .2 .10 | 493648 | 121 | 0 | 000 .000 | +-------------------------------------------------------------------------------+----------------+------------+-----------+---------+
Pages 表示这个文件的总的需要的内存页数
Cached 表示这个文件缓存在内存中的页数
Percent 则是在内存中的比例
我们可以看到确实都被刷出去了。所以大体的流程是可能是
内存用的太多了,可用内存到达了low & min 的水位线
kswapd0 开始回收动态库的缓存。
程序又要运行某段动态库中的代码
然后又触发缺页中断把动态库的部分内容重新放到内存。
其他程序要运行
然kswapd0继续回收动态库的缓存
多个程序轮流获得 CPU 运行,不断将各种动态库加载到内存,提出内存,循环往复打爆磁盘读 IO
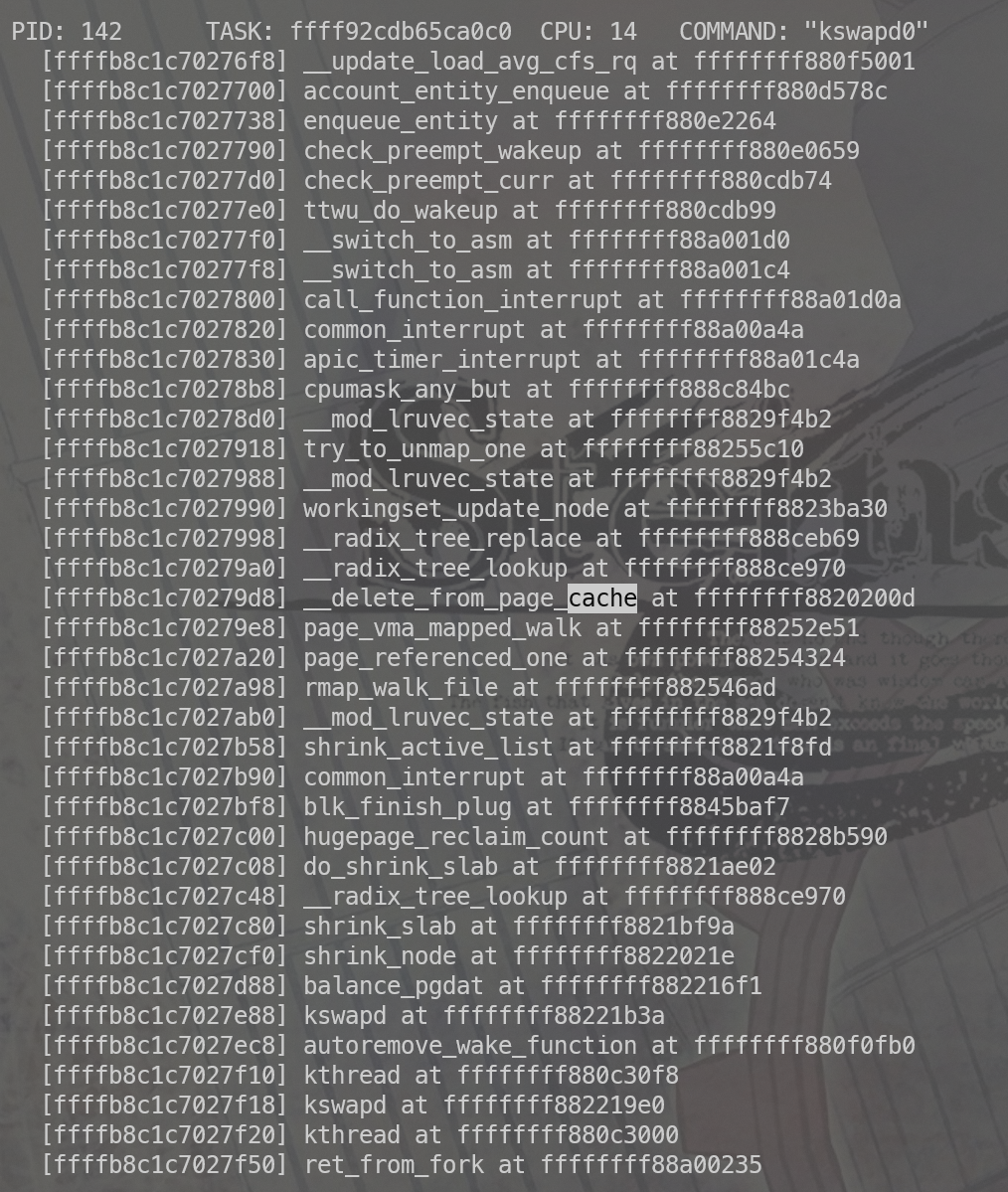
我们手动触发一下kdump看下系统的状态。
kswapd 确实是在page释放
后续在 任叔 那边了解到了更优雅的办法,不一定要用kdump的方式 可以使用 echo ‘l’ > /proc/sysrq-trigger 的方式打印stack。
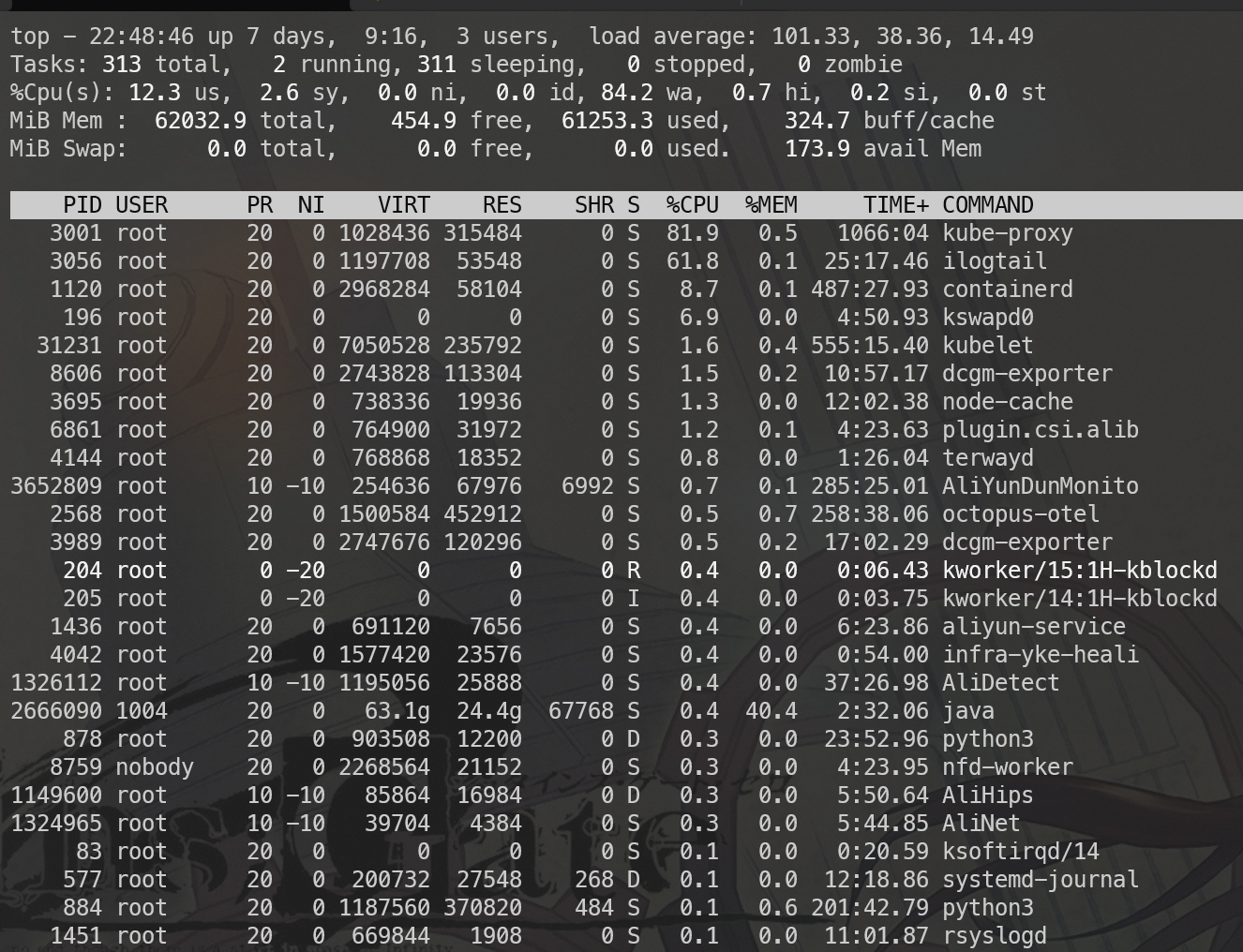
消失的内存 内存不足的时候各类cache才会开始释放,我们开始分析内存的问题。如下图所示:
我们观察到如下情况:
kswapd0 启动了
free&avail 只有1g+ buff/cache 也只有1.5G的样子
java 也只有5g的内存使用,没有其他特别占用内存的进程。
那么问题来了。我的内存哪里去了?
我们把所有的进程加载一起内存不过30g,剩下的内存去哪里了?cache/buffer 也没有多少,估计是让内核占了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 cat /proc/meminfo MemTotal : 63596320 kBMemFree : 433348 kBMemAvailable : 16240 kBBuffers : 852 kBCached : 26580 kBSwapCached : 0 kBActive : 16720 kBInactive : 27111048 kBActive (anon): 3880 kBInactive (anon): 27101972 kBActive (file): 12840 kBInactive (file): 9076 kBUnevictable : 0 kBMlocked : 0 kBSwapTotal : 0 kBSwapFree : 0 kBDirty : 12 kBWriteback : 0 kBAnonPages : 27100712 kBMapped : 105652 kBShmem : 5188 kBSlab : 516752 kBSReclaimable : 47820 kBSUnreclaim : 468932 kBKernelStack : 16512 kBPageTables : 72564 kBNFS_Unstable : 0 kBBounce : 0 kBWritebackTmp : 0 kBCommitLimit : 31798160 kBCommitted _AS : 53252204 kBVmallocTotal : 34359738367 kBVmallocUsed : 0 kBVmallocChunk : 0 kBPercpu : 15360 kBHardwareCorrupted : 0 kBAnonHugePages : 25145344 kBShmemHugePages : 0 kBShmemPmdMapped : 0 kBFileHugePages : 0 kBFilePmdMapped : 0 kBCmaTotal : 0 kBCmaFree : 0 kBHugePages _Total : 0 HugePages _Free : 0 HugePages _Rsvd : 0 HugePages _Surp : 0 Hugepagesize : 2048 kBHugetlb : 0 kBDirectMap4 k : 37127992 kBDirectMap2M : 26834944 kBDirectMap1G : 3145728 kB
Slab 很低
KernelStack 很低
PageTables 很低
这个时候我们看下slab的具体分配吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 Active / Total Slabs (% used) : 9927144 999243428 (99.3 Active / Total Caches (% used) : 10380 / 99380.0 %) Active / Total Size (% used) : 488344. 34K / 512542. 09K (95.3 %) Minimum / Average / Maximum Object : 090503.86 .05K /2913. 43K 5.6 OBJS ACTIVE USE OBJ SIZE SLABS OBJ /SLAB CACHE SIZE NAME 8650926 8650926 100 % 0. 04K 84813 102 339252K nvidia_pte_cache-2782818403 69760 67912 97 % 0. 06K 1090 64 4360K kmalloc-64 61698 28017 43 % 0. 20K 1582 39 12656K dentry 60099 27130 45 % 0. 13K 1541 30 6328K kernfs_node_cache 32096 32096 100 % 0. 50K 1003 32 16048K kmalloc-512 32064 32064 100 % 0. 12K 1002 32 6032K kmalloc-128 26132 29632 97 % 0. 03K 206 128 814K kmalloc-32 26080 26017 96 % 1. 00K 815 32 26080K kmalloc-1024 21760 21760 100 % 0. 02K 85 256 340K kmalloc-16 20076 20076 100 % 0. 09K 478 42 1912K kmalloc-96 18070 13330 73 % 0. 61K 695 26 11120K inode_cache 17850 17850 100 % 0. 04K 175 102 700K Acpi -Namespace 14352 5455 38 % 0. 09K 312 46 1248K vmap_area 14994 14994 100 % 0. 04K 147 102 588K ext4_extent_status 14352 5455 38 % 0. 29K 312 46 1248K vmap_area 12670 11725 92 % 0. 06K 202 64 896K anon_vma_chain 12416 11577 93 % 0. 01K 194 512 776K kmalloc-8 10248 3764 36 % 0. 57K 366 28 5856K radix_tree_node 9072 4018 44 % 1. 09K 324 29 9184K ext4_inode_cache 8992 8992 100 % 0. 12K 281 32 1124K seq_file 7461 3473 38 % 1. 09K 309 29 9888K ext4_inode_cache 7527 7527 100 % 0. 10K 193 39 772K anon_vma 7476 7243 96 % 0. 29K 278 42 1424K kmalloc-192 6486 6115 86 % 0. 69K 141 46 4512K ovl_inode 6486 4047 62 % 0. 69K 141 46 4512K ovl_inode 6300 6300 100 % 0. 71K 140 45 4480K shmem_inode_cache 5734 5568 97 % 2. 68K 122 47 3904K proc_inode_cache 5350 5350 100 % 0. 16K 214 25 856K sigqueue 5265 4740 97 % 0. 10K 135 39 540K buffer_head 4688 4688 100 % 2. 00K 293 16 9376K kmalloc-2048 4536 4536 100 % 0. 19K 108 42 864K cred_jar 4505 4505 100 % 0. 05K 53 85 212K ftrace_event_field 4096 4096 100 % 0. 02K 16 256 64K selinux_file_security 4096 4096 100 % 0. 02K 16 256 64K selinux_file_security 3104 3104 100 % 0. 25K 97 32 776K skbuff_head_cachervation 2958 2958 100 % 0. 08K 58 51 232K task_delay_info 2912 2912 100 % 0. 07K 52 56 208K Acpi -Operand 2720 2720 100 % 0. 02K 16 170 64K avtab_node 2436 2436 100 % 0. 14K 87 28 348K ext4_groupinfo_4k 1856 1856 100 % 0. 25K 58 32 464K kmalloc-256 1856 1856 100 % 0. 06K 29 64 116K ebitmap_node 1632 1632 100 % 0. 04K 16 102 64K pde_opener 1600 1600 100 % 0. 16K 64 25 256K sigqueue 1512 1512 100 % 0. 19K 36 42 288K proc_dir_entry 1460 1460 100 % 0. 05K 20 73 80K mbcache 1408 1408 100 % 0. 25K 44 32 352K pool_workqueue 1380 1380 100 % 1. 06K 46 30 1472K signal_cache 1334 1334 100 % 0. 69K 29 46 928K sock_inode_cache 1292 1292 100 % 0. 12K 38 34 152K jbd2_journal_head 1288 1288 100 % 0. 07K 23 56 92K eventpoll_pwq 1168 1168 100 % 0. 05K 16 73 64K Acpi -Parse 1143 1126 98 % 8. 19K 381 3 12192K task_struct 1037 1082 100 % 0. 06K 79 64 28K ext4_io_end 1088 1088 100 % 0. 06K 17 64 68K ext4_io_end 897 897 100 % 0. 10K 23 39 92K blkdev_ioc 896 896 100 % 0. 07K 16 56 64K jbd2_journal_handle 850 636 74 % 0. 31K 34 25 272K bio-0 828 828 100 % 0. 69K 18 46 576K files_cache 784 784 100 % 0. 56K 28 48 448K skbuff_fclone_cache
nvidia_pte_cache-2782818403 非常奇怪,但是 8650926 * 0.04K = 300M+ 这个就很少。
不过这个pte就很令人产生遐想,会不会是page table。如果说每个这个pte-cache背后都有一个对应的page那么这就是很大的内存了。假设如果这个每个object 背后对应的都是一个page的话, 8650926 * 4k(单个page大小) = 30g+ 这个跟我们丢掉的内存空间确实比较接近,非常值得怀疑。
搜一下nvidia_pte_cache这个东西。
https://github.com/NVIDIA/open-gpu-kernel-modules/blob/main/kernel-open/nvidia/nv.c#L414
看起来是gpu驱动里面的东西,我们看下是不是调用这里面的方法申请到的内核的内存。
看了下里面大部分都是nv开头的函数,我们重跑一遍我们的程序,然后看下对应带nv字样的函数调用数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 ./funccount 'nv*' FUNC COUNT nv_drm_fence_supported_ioctl 2 nvidia_dev_get 2 nvidia_dev_put 2 nvkms_alloc_ref_ptr 2 nvkms_close_gpu 2 nvkms_free_ref_ptr 2 nvkms_memcpy 2 nvkms_open 2 nvkms_open_common 2 nvkms_open_gpu 2 nvkms_snprintf 2 nvkms_strcmp 2 nvkms_close 3 nvkms_copyin 3 nvkms_copyout 3 nvkms_ioctl 3 nv_drm_get_dev_info_ioctl 4 nvidia_read_card_info 4 nv_get_usermap_access_params 6 nv_is_gpu_accessible 6 nvkms_free_timer 6 nvkms_memset 18 nv_vm_map_pages 18 nv_vm_unmap_pages 21 nv_assert_not_in_gpu_exclusion 24 nv_is_uuid_in_gpu_exclusion_li 24 nvkms_free 26 nv_open_device 26 nvkms_alloc 27 nvidia_close_callback 37 nv_close_device 39 nvkms_call_rm 48 nvidia_modeset_rm_ops_alloc_st 52 nvidia_modeset_rm_ops_free_sta 52 nv_alloc_user_mapping 59 nvidia_mmap_sysmem 59 nv_add_mapping_context_to_file 65 nvidia_frontend_mmap 65 nvidia_mmap 65 nvidia_mmap_helper 65 nv_free_user_mapping 74 nv_get_file_private 81 nvidia_ctl_close.constprop .0 81 nvidia_vma_release 83 nv_alloc_file_private 87 nvidia_open 87 nvidia_frontend_open 89 nv_put_file_private 89 nvidia_close 118 nvidia_frontend_close 121 nv_match_dev_state 156 nv_get_ctl_state 189 nvidia_rc_timer_callback 440 nvidia_frontend_poll 660 nvidia_poll 660 nv_create_dma_map_scatterlist 724 nv_dma_map_scatterlist.constpr 724 nv_dma_map_scatterlist.part .0 724 nv_load_dma_map_scatterlist 724 nv_map_dma_map_scatterlist 724 nv_alloc_system_pages 728 nv_destroy_dma_map_scatterlist 738 nv_unmap_dma_map_scatterlist 738 nv_free_system_pages 743 nvidia_isr 3114 nvidia_isr_msix 3114 nv_uvm_event_interrupt 3114 nvidia_ioctl 4386 nvidia_frontend_unlocked_ioctl 4389 nv_alloc_contig_pages 7463 nv_free_contig_pages 7469 nv_alloc_pages 8191 nv_compute_gfp_mask 8191 nv_dma_map_alloc 8191 nv_dma_map_pages 8191 nvos_create_alloc 8191 nv_requires_dma_remap 8191 nv_dma_unmap_alloc 8212 nv_dma_unmap_pages 8212 nv_free_pages 8212 nvos_free_alloc.isra .0 8212 nv_encode_caching 8254 nv_alloc_kernel_mapping 45008 nv_free_kernel_mapping 45010 nv_printf 62442 nv_get_kern_phys_address 8250125
观察这些函数,有不少值得怀疑的对象比如 nvos_create_alloc nv_alloc_pages。
结合开源的代码我们看两个函数 。这两个函数的功能差不多,同时他们之间也是依赖关系,所以我们选择参数少的nvos_create_alloc进行分析 ,函数定义如下。
1 2 3 4 5 static nv_alloc_t *nvos_create_alloc ( struct device *dev, NvU64 num_pages )
我们跟踪下这个函数的参数,第二个参数是page的数量即下边的arg1,如果所有的申请跟我们消失的内存大致对的上则证明我们的分析是合理的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <...>-2657537 [000 ] .... 637715.039848 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x1 java-2657537 [001 ] .... 637715.048983 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x20 java-2657537 [001 ] .... 637715.049273 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x40 java-2657537 [001 ] .... 637715.052133 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x20 java-2657537 [001 ] .... 637715.052364 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x40 java-2657537 [001 ] .... 637715.052708 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x20 java-2657537 [001 ] .... 637715.052978 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x40 java-2657537 [001 ] .... 637715.053273 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x1 java-2657537 [001 ] .... 637715.053505 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x2 java-2657537 [001 ] .... 637715.053536 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x2 java-2657537 [001 ] .... 637715.058549 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x2 java-2657537 [001 ] .... 637715.058569 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x2 java-2657537 [001 ] .... 637715.061134 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x2 java-2657537 [001 ] .... 637715.061145 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x2 java-2657537 [001 ] .... 637715.063490 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x4 java-2657537 [001 ] .... 637715.063676 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x2 java-2657537 [001 ] .... 637715.064055 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x13 java-2657537 [001 ] .... 637715.064260 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x80 java-2657537 [001 ] .... 637715.074803 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x100 java-2657537 [001 ] .... 637715.075544 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x4 java-2657537 [001 ] .... 637715.081795 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x3 java-2657537 [001 ] .... 637715.084390 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x3 java-2657537 [000 ] .... 637716.029619 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x200 java-2657537 [001 ] .... 637716.061426 : myprobe : (nvos_create_alloc+0x0 /0x1a0 [nvidia]) arg1=0x80 .... 省略若干
使用脚本处理结果
1 2 3 4 5 6 7 8 9 10 11 #!/bin/ bash # 从管道读取输入 input=$(cat) # 使用 grep 和 awk 提取所有包含 'arg1=' 的行中的十六进制数值 # 然后将这些十六进制数值累加 total_sum=$(echo "$input" | grep 'arg1=' | awk -F'arg1=' '{print $2}' | awk '{sum += strtonum($1)} END {print sum}' ) # 输出最终的总和 echo "十六进制数的和为: $total_sum"
最后累计得到 8231127 * 4k / 1024 /1024 = 31.39G 与消失的内存接近。最初pte 推算猜测,本次使用跟踪nvos_create_allo 对比应该可以确定内存确实是被nv的模块给申请走了,同时这部分内存确实是在分配在内核空间中。
此时如果我们 kill 掉进程之后该部分内存会被释放,所以说并不存在内核/driver层面的泄露,而是业务使用的时候没有释放,或者还没走到释放的逻辑就卡住了。
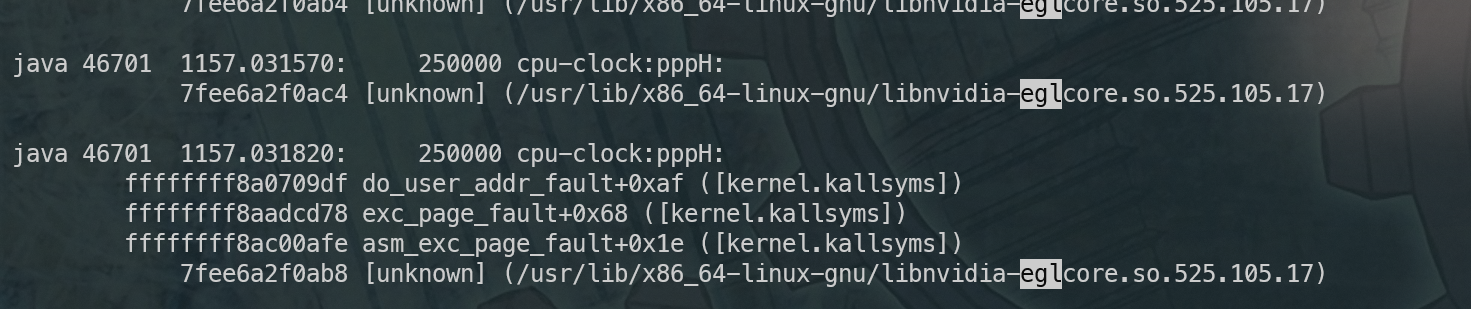
内存是被如何分配走的? perf 了一下除了一个egl的lib没有什么值得注意的,这个egl应该就是申请内存的玩意,但是没有符号表。就很继续分析了,调用链也推不太清楚。
在没有明确具体过滤查找的某些系统调用情况下strace也很难获取到有用的信息。内容过多。
到这里实在没有办法搞了。业务代码太复杂了。此时我在朋友圈吐槽阿里排查的人不专业,也不给我们升级,刚好让之前的老板看到了。就在群里聊了起来。此时F叔说可能是 CUDA 申请的。还发了一小段文档。感觉说的简直太有道理了,必定就是这个了。感谢F叔的开悟。
业务的大体逻辑是opengl 图片渲染。我以为的流程大概是(实际上不是) opengl→ egl.so → cuda xxx → nvxx.ko(内核)在gpt的帮助下分别实现了如下的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <cuda_runtime.h > #include <stdio.h > int main ( const size_t size = 100 * 1024 * 1024 ; void *hostPtr; cudaError_t err; while (1 ) { err = cudaHostAlloc (&hostPtr, size, cudaHostAllocDefault); if (err != cudaSuccess) { fprintf (stderr, "cudaHostAlloc failed (%s)\n" , cudaGetErrorString (err)); break ; } printf ("Allocated memory at address: %p\n" , hostPtr); } return 0 ; }
cudaHostAlloc 这个分配的内存会算到进程的内存中,会被 OOM 掉。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <opencv2/opencv.hpp > #include <cuda_runtime.h > __global__ void MirrorFlipKernel (unsigned char *data, int width, int height) { int x = blockIdx.x * blockDim.x + threadIdx.x ; int y = blockIdx.y * blockDim.y + threadIdx.y ; if (x < width && y < height) { int mirroredX = width - 1 - x; data[y * width + x] = data[(height - 1 - y) * width + mirroredX]; } } int main ( cv ::Mat image = cv ::imread ("pic.jpg" ); if (image.empty ()) { std ::cerr << "Could not open or find the image" << std ::endl; return -1 ; } int width = image.cols ; int height = image.rows ; for (int i = 0 ; i < 100000 ; ++i) { unsigned char *d_data; size_t size = width * height * sizeof (unsigned char); cudaMallocManaged (&d_data, size); cudaMemcpy (d_data, image.data , size, cudaMemcpyHostToDevice); int blockSize = 16 ; dim3 dimGrid (ceil (width / float (blockSize)), ceil (height / float (blockSize)), 1 ); dim3 dimBlock (blockSize, blockSize, 1 ); MirrorFlipKernel <<<dimGrid, dimBlock>>>(d_data, width, height); cudaMemcpy (image.data , d_data, size, cudaMemcpyDeviceToHost); } return 0 ; }
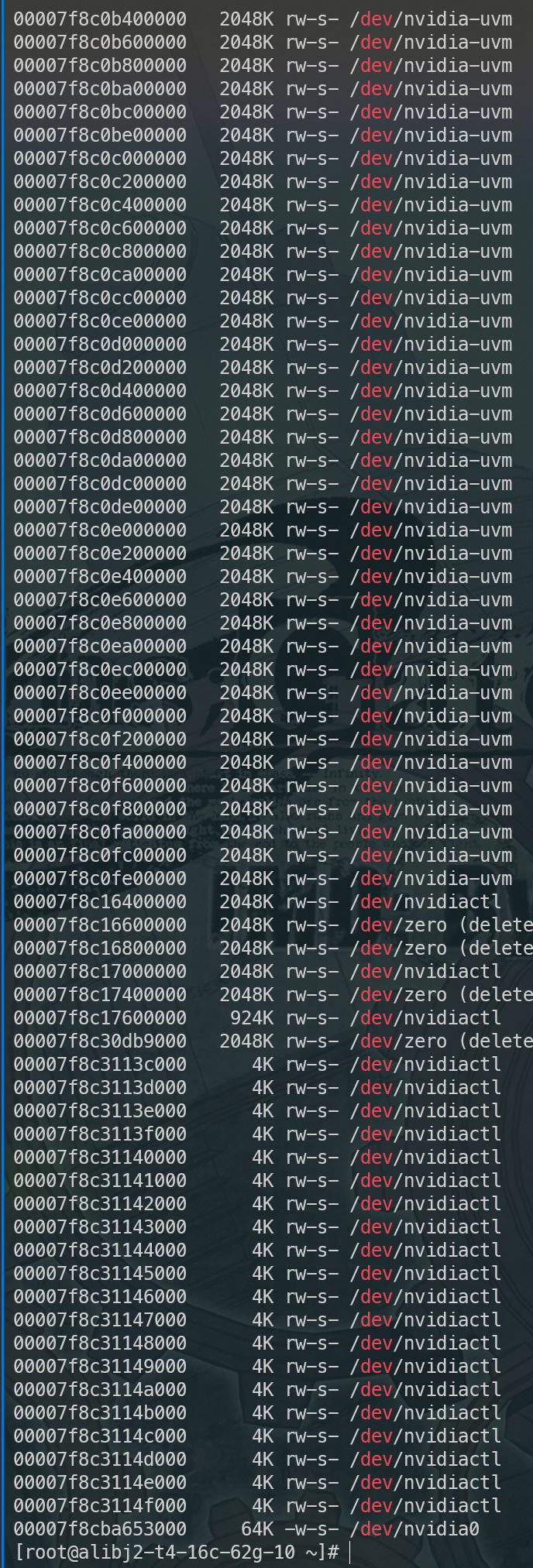
cudaMallocManaged 这个虽然能复现类似的场景,但是有一点明显不同。会有大量的uvm设备交互,同时会有uvm的进程cpu使用率升高。同时也能使用工具看到pmap看到相关的分配,而之前是完全没有办法看到的。这个是跟之前的不一致。
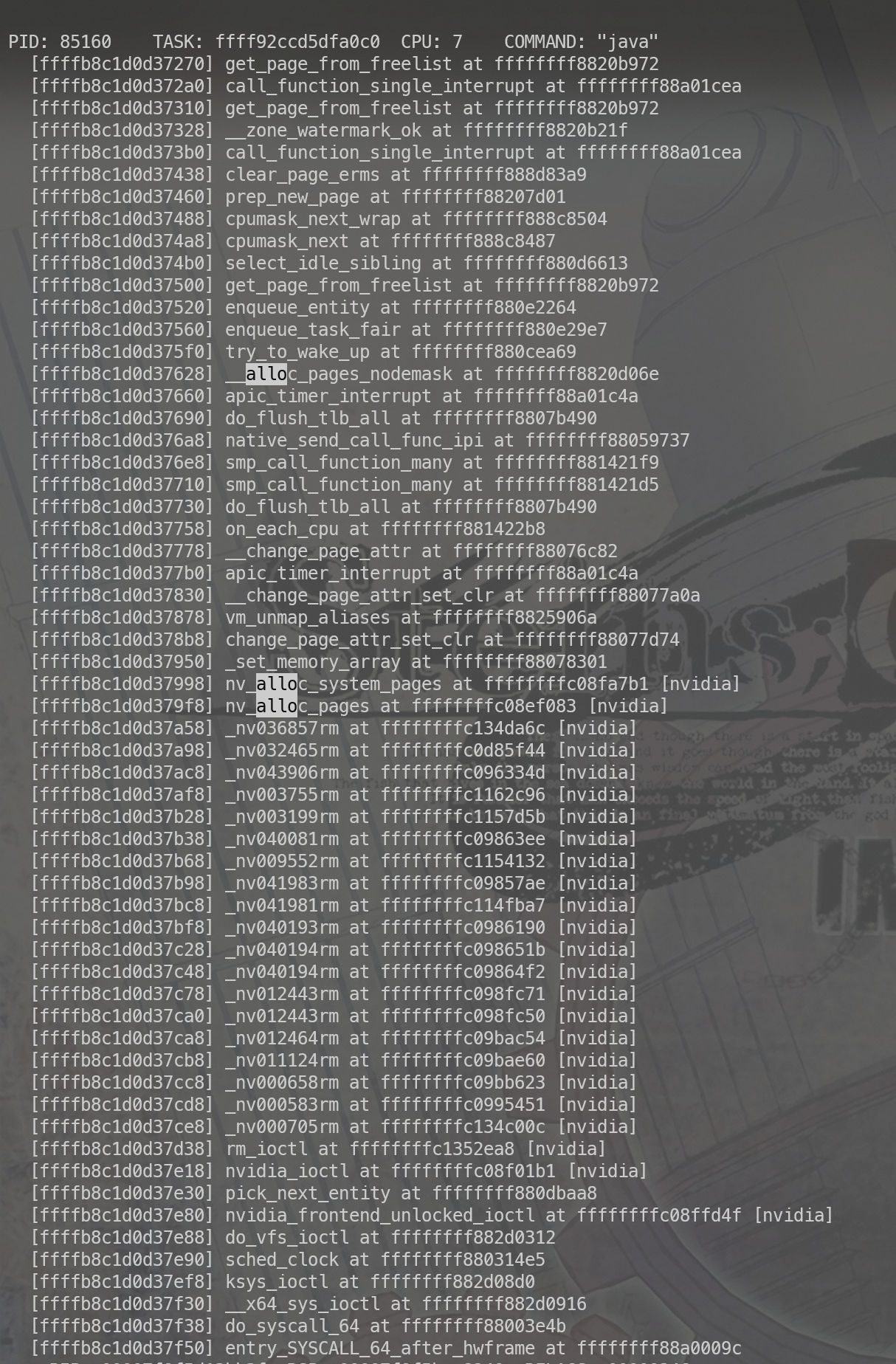
只能回去又扒之前的kdump,这里面有些信息,至少说是内核态的分配路径大体是清楚的了,但是用户态的逻辑依然不清楚。
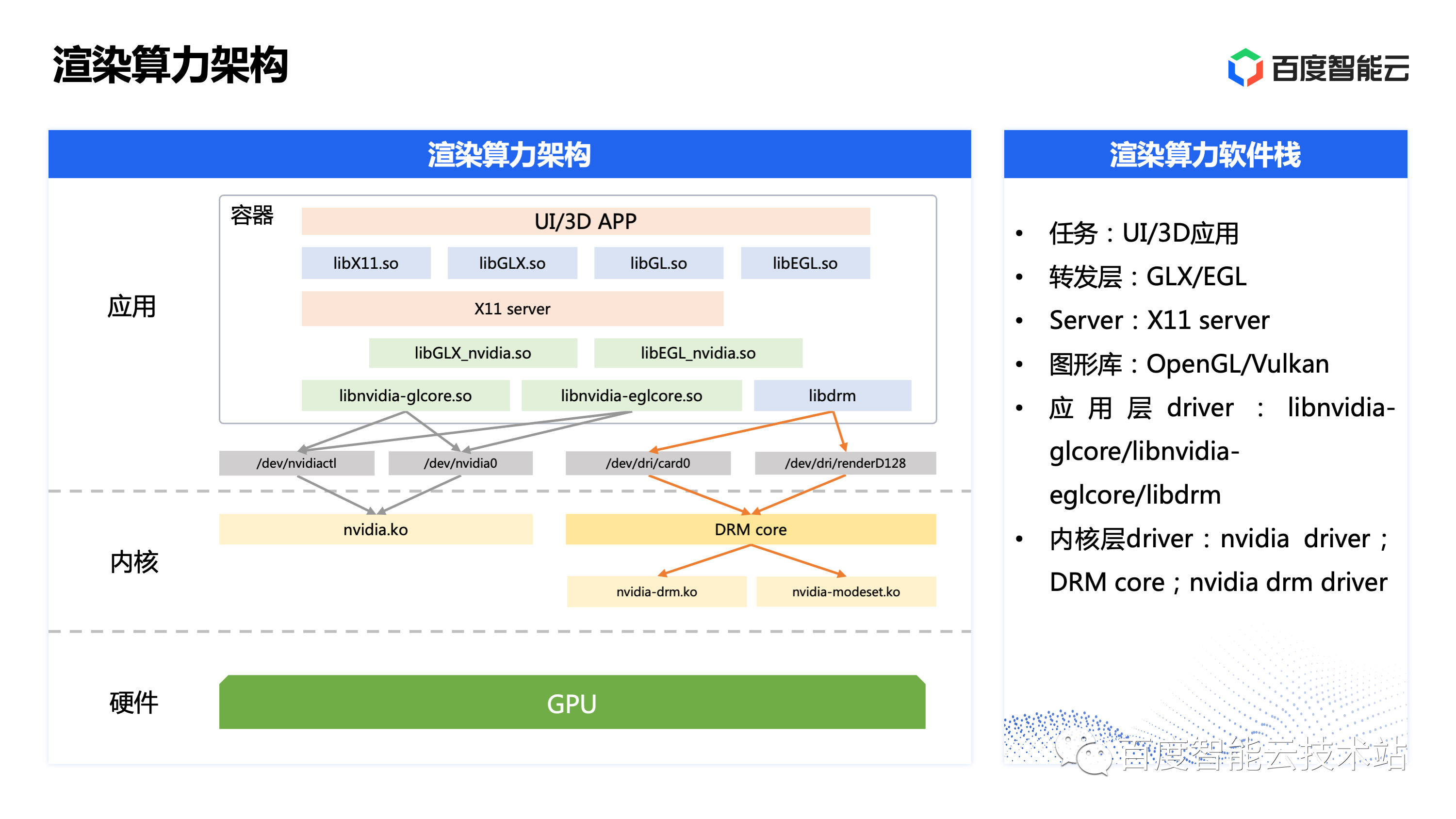
在网上扒到了一张百度的图,才发现跟自己的猜测不太一样。opengl这一波的调用并不依赖CUDA相关的东西。
不过想想也是合理。毕竟CUDA出现的比这玩意要晚的多,而且更多是为了用来支持非图形计算的场景。只是自己之前基础知识过于薄弱,同时之前在工作中使用GPU的场景全部是深度学习场景,都是基于CUDA的,因此并不知道他们的关系。好蠢~
知道了opengl 这部分的内容后开始尝试写程序复现,但是学了一顿没有学明白。也没有找到讲解相关内存分配逻辑的文章。
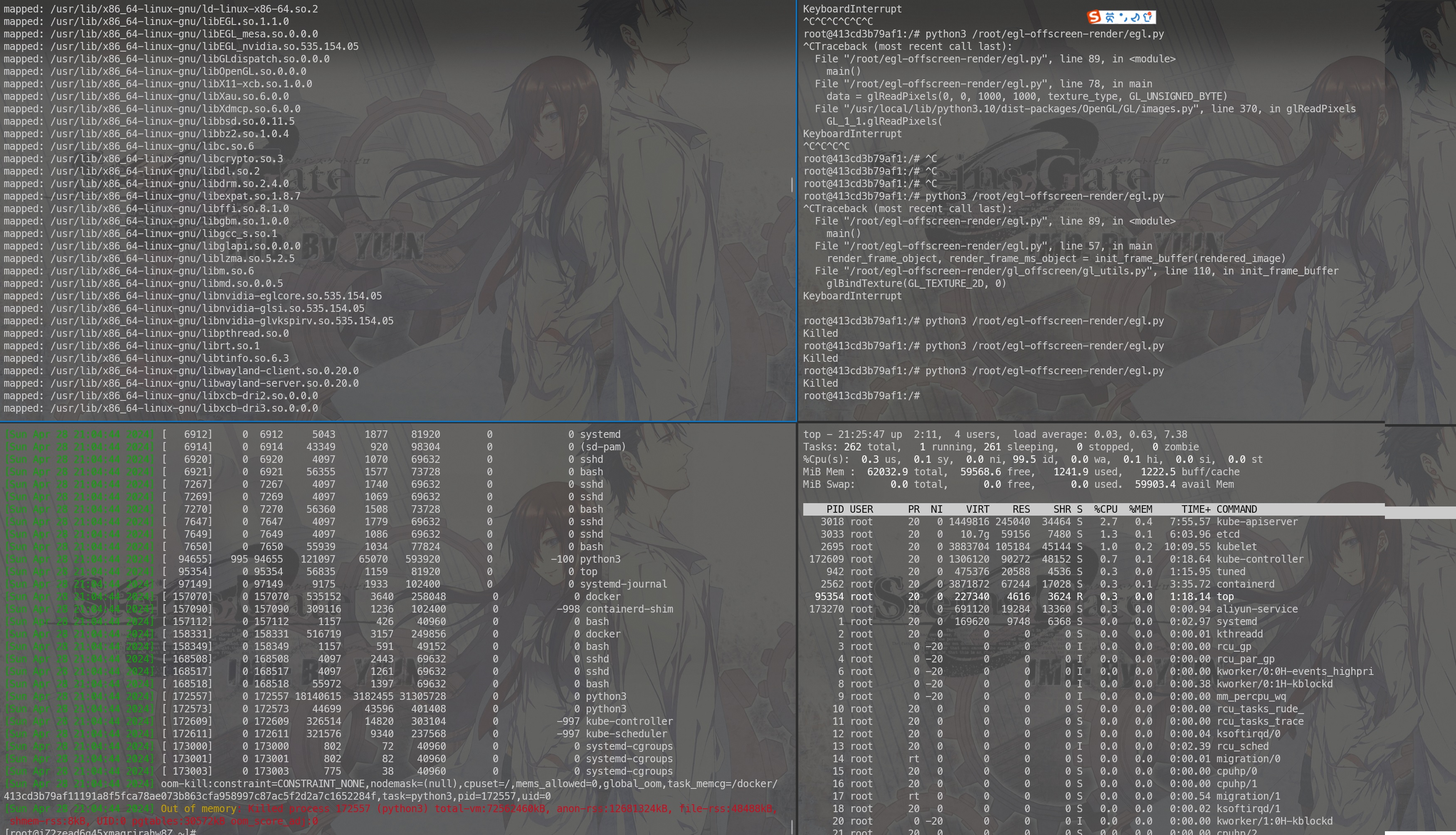
只能上网上扒个项目https://github.com/KernelA/egl-offscreen-render ,改了改代码,反复申请buffer不释放成功的进行了复现。
从API的层面看初始化contex 之后 调用 glBindFramebuffer→glFramebufferTexture2D 之后内核中的内存就已经分配了。
eglDestroyContext 之后则内存释放。(可能有其他的方式我不知道)整个Linux的图形系统比较难以学习。
暂时不继续分析了。大体上我们知道在用户态能够通过某些手段分配到内核中的内存,进而耗尽系统的内存。cgroup v1 中kmem 中是不会统计到这部分内核中申请的内存,当然v2 也不会。
小插曲 这部分测试完了之后我在想会不会是老黄舅舅比较垃圾,实现的方式不太好。于是把代码跑到了AMD 的 GPU 上,打算让苏妈好好教教他老黄舅舅做人。结果大吃一惊,不但 AMD 也会申请内核中的内存,而且貌似实现的方式还有内存泄露,即使 kill 掉用户的进程内核中申请的内存仍然无法释放。
还得是她老黄舅舅技高一筹。
为什么Pod为什么没有OOM? 从之前的排查看我们的 Pod 的内存仍然没有超过 cgroup 的限制,没有因为触发 cgroup OOM 是预期内的。但是系统整体内存已经不足了。这种场景难道不应该触发 OOM 去杀死进程吗?
很遗憾,并没有。
关于为什么没有OOM的问题一直困扰了我很久,做了如下3组实验。
在新启动的一台空机器中跑docker中会复现,但是经过一段时间可能是几十秒也可能是几分钟最终会被 进程会被 OOM 掉。
在 K8S 中几乎是必现。从未被kill掉。为此我还特意调整了docker 的oom adj 让他们的oom score的预期尽量一致。
在跑 K8S 的节点上起 docker 跑复现的程序,也必然会复现长期卡死的一个状态。
一筹莫展之际。任叔提供了一个重要的线索。low水位下内存的频繁换入换出本身就会抑制内存的分配(因为太卡了,跑的慢了)。同时提了2个比较有用的特性:
一个是阿里云/龙蜥的内核提供了一个特性能够根据pid锁定page
另外一个是echo l > sysrq-trigger 可以打印cpu上的stack
基于上述重要的线索,我们大体上可以做一个推测:
有大量的程序(这个大量很重要)在运行,他们运行就要把他们的代码加载到内存中。
很多程序在运行的过程中大量程序轮流获得cpu,程序轮流加载到内存中。
系统就变的非常的慢。
我们那个申请内存的程序在执行过程中也会经历大量的缺页中断从磁盘加载动态库到内存,消耗大量时间。所以分配内存的逻辑走不了几次,系统卡住也不会申请很多内存,系统的整体内存减少的不多。
同时因为这部分被各个程序运行动态库占用的 page 是可以被释放的,所以整体水位仍然没有达到 min 水位。
所以分配内存的时候不会触发oom killer。
如过我们的猜测是正确的话。如果我们能锁定我们系统中运行程序的 page,那么他们的运行速度会变得很快,应该会被kill。
我们周期性的触发 echo l > sysrq-trigger 会发现会有相当一部分cpu栈是在触发缺页中断从磁盘加载程序到内存,同时也会有相当一部分是page被释放(因为内存比较少了)。
第一个比较简单我们先按照第一个去验证。
失败了,这个显然也是不太符合预期的。看起来好像是动态库的没办法锁定。如下图所示,第二次执行的时候cache已经被刷出去一半了。
我们通过第二种方式从侧面观察看看程序运行所处的路径
1 2 3 4 5 6 7 8 9 10 #!/bin/ bash # 将脚本放入后台执行,避免阻塞当前终端 { while true ; do echo l > /proc/ sysrq-trigger sleep 1 # 暂停一秒 done } &
通过这个脚本可以周期的打印stack
只看到申请的了,没有看到释放的记录。侧面观察的方式也是失败了。
可能还是要从方案1入手,但是除了二进制还要想办法把动态库也锁住。
github上找到了一个利用mlock机制锁定动态库的项目。大体上的思路如下:
程序启动的时候调用 mlockall 方法,则此进程中的全部内存会被锁定不会被换出。
扫描 /proc/pid/maps 获取到全部进程中使用的动态库。
mmap的方式将这些lib加载一遍,由于开始执行了mlockall,所以这些lib的page全部锁定住。
所以我们需要做如下操作:
1 2 3 4 5 6 7 8 9 10 11 12 python3 /root/egl-offscreen-render/egl.py ps -ef |awk '{print $2}' |grep -v PID |xargs -I {} echo {} > /proc/u nevictable/add_pid git https : cd prelockd make install vim /usr/local/etc/prelockd.conf 增加python3 /usr/local/sbin/prelockd -c /usr/local/etc/prelockd.conf ps -ef |awk '{print $2}' |grep -v PID |xargs -I {} echo {} > /proc/u nevictable/add_pid
我们观测到进程被预期内的 OOM 掉了
虽然并不是特别直接的观测到内存分配释放的路径,但是大体上应该能够推断是:
程序运行时依赖的动态库的page被不断地重新释放与加载
同时磁盘的读io被打爆,重新加载会消耗大量的时间,因此导致了导致程序本身运行的很慢
因此申请内存的速度减缓
比较难进一步达到oom-killer需要的最低水位线。
所以程序没有被oom kill掉。
整体上我们遇到的问题大体上分析的差不多了。
问题分析
为什么我们的宿主机notReady了?
因为宿主机kubelet运行的非常慢没办法上报状态了。
为什么我们的kubelet运行的非常的慢?
同时kubelet运行需要的各种依赖动态库被刷出内存了,运行要重新加载,同时读io被打爆了,将程序运行时的依赖加载到内存当中就要花很久。所以非常慢。
为什么kubelet运行的各种动态库依赖被刷出内存了?
因为系统内存不足。
为什么系统内存不足了?
业务代码申请了大量的内存。
业务运行在Pod当中配置了合适的内存Limit为什么cgroup的限制没有OOM掉业务进程?
[推测]因为业务申请的一部分内存是通过驱动申请的这部分内存,这部分内存cgroup统计不到,没有超过cgroup的限制。所以没有oom。
即使cgroup没有限制住,当整体内存不足的时候,系统整体的oom为什么也没有起作用?
[推测]程序运行时依赖的代码&lib的page被不断地重新释放与加载,同时磁盘的读io被打爆,重新加载会消耗大量的时间,因此导致了导致程序本身运行的酒很慢,因此申请内存的速度减缓,比较难进一步达到oom-killer需要的最低水位线。所以程序没有被oom kill掉。
解决办法 这里指的解决办法是防止因为业务的错误用法,或内存用量估计不足导致把集群打爆。
潜在可行的解决办法
可能社区或者厂商能够记录进程通过driver的内存,同时统计到cgroup当中利用cgroup的oom机制进行oom。不确定是否能够实现。
使用earlyoom/oomd 不要等到大量的page被释放程序运行的缓慢时再进行oom,将这个过程提前到系统整体运行状态还不错的时候。如下图所示(earlyoom)。
降低node-eviction-rate比如降到0.0003查不多1小时驱逐一个node,集群打爆的风险大大降低。不出现大规模宕机事件应该不会有什么风险,如过出现大规模宕机事件(比如一个tor掉电,一个机会掉电,或者某个厂商的某个az挂了),要人工介入加速驱逐。同时如果某些业务比较点背的跟异常业务重合度比较高,可能出现正常业务,也没办法依赖驱逐机制重建。
关闭k8s node not ready 的驱逐策略,自己写控制器实现更灵活的驱逐策略。
其他 关于结论 稀里糊涂查了好多东西,也查了很多不太相关的方向,比较偏的方向就不往上写了。整体上逻辑链中有不少仍然是缺失的。也没有做源码级别的分析跟调试。所以得到的结论可能也是错的。但是好像能自圆其说。
关于OOM 理论上只要内存申请的足够多,哪怕是在用户空间申请的,仍然会造成系统卡死的问题。但是这么多年我竟然不知道,同时也很少见到相关的文章。当我找到了一些能够解决系统卡死了仍然没有 OOM的开源项目时,我又惊讶的发现这个问题已经存在很久了。而且貌似内核侧仍然没有明显的改善。从4.19-5.10-6.1 都能复现。
关于Cgroup Cgroup 仍然有很多资源我们没办法限制,我们的节点仍然会面临着被无法限制的某类资源打爆的可能性,不过好在看到内核社区与厂商合作仍然有很多种资源的限制能力在持续跟进开发。
参考文章 https://github.com/freelancer-leon/notes/blob/master/kernel/graphic/Linux-Graphic.md
https://zhuanlan.zhihu.com/p/511791039
https://www.khronos.org/opengl/wiki/Memory_Model
https://forums.developer.nvidia.com/t/cuda-unified-memory-usage-is-not-accounted-by-linux-cgroup/264689
https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__MEMORY.html
https://mp.weixin.qq.com/s/6cBKEolypVPcAbzu4GwS3A
https://time.geekbang.org/column/article/75797
https://www.bluepuni.com/archives/linux-memory-reclaim/
https://help.aliyun.com/zh/alinux/user-guide/memcg-oom-priority-policy
https://help.aliyun.com/zh/alinux/support/causes-of-and-solutions-to-the-issue-of-oom-killer-being-triggered
https://cloud.tencent.com/developer/article/2309788
https://lwn.net/Articles/666024/
https://www.kernel.org/doc/Documentation/sysctl/vm.txt
https://blog.acean.vip/post/linux-kernel/gai-shu-linuxnei-he-san-jia-ma-che-zhi-nei-cun-guan-li
https://www.kernel.org/doc/html/v5.0/vm/unevictable-lru.html
https://gitcode.net/openanolis/cloud-kernel/-/blob/linux-next/mm/unevictable.c?from_codechina=yes
https://docs.kernel.org/admin-guide/sysrq.html
https://www.wang7x.com/2021-01-26-linux-oom-killer/
https://plantegg.github.io/2020/11/15/Linux内存--pagecache/
https://plantegg.github.io/2020/11/15/Linux内存--HugePage/
https://help.aliyun.com/zh/alinux/support/solutions-to-memory-fragmentation-in-linux-operating-systems
https://www.reddit.com/r/linux/comments/56r4xj/why_are_low_memory_conditions_handled_so_badly/
https://superuser.com/questions/406101/is-it-possible-to-make-the-oom-killer-intervent-earlier
https://lkml.org/lkml/2013/3/18/812
https://github.com/facebookincubator/oomd
http://0fd.org/2021/07/13/cgroup-memory-controller-of-mlock/
https://github.com/hakavlad/prelockd
https://github.com/datenwolf/fmlock/blob/master/fmlock.c
https://kubernetes.io/zh-cn/docs/concepts/architecture/nodes/#rate-limits-on-eviction
https://blog.csdn.net/qazw9600/article/details/123742808
https://cloud.tencent.com/developer/article/2363233