haystack 指北
序
haystack 是facebook 开发的对象存储系统,用来存储facebook的照片,面对海量的图片数据,从中取回一张图片确实很像大海捞针,文章的名字还是比较有有意思的,相关的设计发表在了osdi 原文链接 文章总体分为6大部分,主要总结了facebook遇到的问题,总结过去遇到的问题,回顾过去的解决方案,进而规避过去方案的不足从而设计了haystack来解决之前的问题,并在文章的最后进行了性能相关的分析。本博文主要摘取重要部分进行摘录,并进行进一步讨论和研究,同时回避了CDN相关的章节。
简介
一些数字
- 6500亿张照片
- 2.6万亿 张图片
- 20PB
- 每周10亿张新增照片
- 每周新增存储60TB
- 峰值请求100万/s
未来这些数字会持续上涨,基础设施将会面临非常大的挑战。
业务特征
一次写,频繁的读取,不修改,很少删除。
过去的经验
使用posix文件系统存储文件
问题: 当文件数量增加时获取一个图片需要多次io,磁盘io有限,所以会导致获取图片效率降低。
- 原因
- 读取文件的过程是
- 读取目录元数据获取文件inode
- 读取文件inode
- 读取真实文件。
- 上面的步骤据需要将元数据缓存到内存当中
- 元数据中有大量对于业务场景不需要的数据
- 创建时间
- 修改时间
- 权限
- 组
- etc…
- 元数据中有大量对于业务场景不需要的数据
- 当文件过多时目录的元数据会变得越来越大,读取目录时就需要多次IO,同时由于目录元数据太大能cache能缓存的目录元数据会下降,频繁的被淘汰,导致经常要重新从磁盘读取目录元数据,导致io增加。
- 读取文件的过程是
haystack
Facebook设计了haystack为了解决上述问题
- 高吞吐低延时: 减少图片元数据并且保存在内存当中
- 容错:haystack复制到了多地,一台机器挂了备用的可以顶上来。
- 性价比: 成本下降了28%,提供的请求提升了4倍。
- 简洁:刻意保持简单。
过去的设计
基于NFS的设计
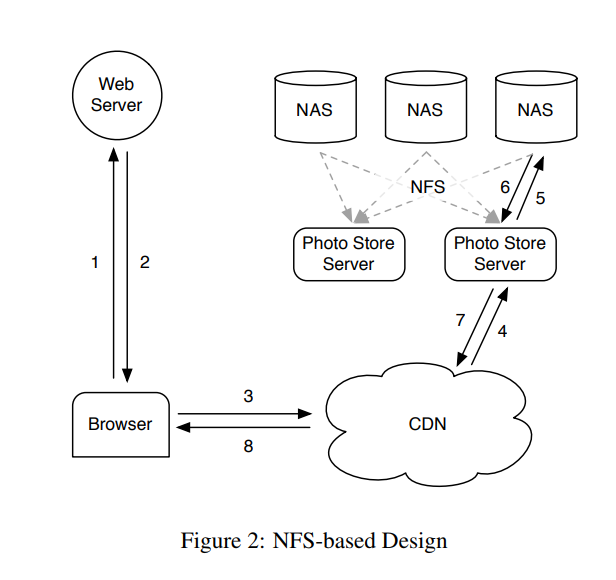
背景
CDN 并不能解决所有问题,facebook面临着大量的长尾请求(很久之前上传的照片)。而这个问题需要自己去解决。
设计
整体图片存储系统分为三层
- 图片存储系统
- 第一层 CDN 缓存
- 第二层 PhotoStorageServer 图片路由逻辑
- 第三层 Nas 最终文件存储
图片文件存储在NAS上, NAS被mount到 PhotoStorageServer上面,PhotoStorageServer 根据文件的URL解析得到完整的文件目录,在NFS上读取数据并返回。
期初在每个目录下存储了几千个文件,导致读取一个文件都有可能产生10个IO,这是由于NAS设备管理元数据的机制造成的,因为目录的blockmap不能被设备有效缓存,后来将每个目录的文件减少到了数百个后系统仍然需要3个IO来获取一个图片,一个读取目录元数据到内存,第二个装在inode到内存,最后读取文件内容。
为了继续减少磁盘IO操作,让图片存储服务器缓存NAS设备返回的问价句柄,并且在内核中添加了通过文件句柄打开文件的接口,然而这个改动并没有起到很好的效果,同样是因为长尾效应,并且存储服服务器不能缓存所有的文件句柄,因为这么做的成本过于高。最终意识到,存储系统使用缓存对减少磁盘IO操作是有限的,图片存储服务器最终还是要处理长尾的请求。
- TIPS: 使用缓存的方式似乎已经行不通了,所以面对长尾的请求只能想方设法通过别的办法减少磁盘IO。
讨论
面对NFS设计的瓶颈,facebook讨论了是否可以构建一个类似GFS的系统,而他们大部分的用户数据都是存在Mysql中,文件存储主要用于日志图片存储,NAS对这些场景提供了很高性价比的解决方案,此外,他们也有hadoop用于海量日志数据处理,对于图片的长尾问题 Mysql NAS Hadoop 都不太合适。
困境
是现有的存储系统没有一个合适的ram-to-disk的比例,系统需要缓存所有的文件系统元数据,在基于NAS的方案中,一个图片对应到一个文件,每个文件至少需要一个inode 大约在 几百个byte,所以Facebook决定构建一个定制的存储系统,减少每个图片的元数据,以便内存能够缓存所有的元数据。
haystack设计和实现
haystack的设计就是为了用来解决系统之前的瓶颈的: 磁盘IO操作。接受长尾请求带来的磁盘IO。
核心思想
- 一个图片存为单独一个文件会导致太多的元数据
- 删除无用的元数据,haystack维护一个大文件,小文件分布在大文件中,haystack自行维护文件的offset,控制文件数量.
- 元数据太大无法缓存
- haystack删除了无用的元数据,仅保留图片相关的基本元数据
- 减少除了访问真实文件之外的IO操作
- 使用单独的大文件,不需要每个文件都要重新去加载数据,在内存保存了所有的元数据
TIPS: 元数据分为两种需要注意区分 一种 是应用元数据 一种是 文件系统元数据 ,前者用来构建浏览器访问的url,后者用于在磁盘上进行文件检索。
设计概览
haystack 分为三个组件
- store
- 持久化存储系统,负责管理图片元数据与图片数据持久化。
- store将文件存储在物理卷上,每个机器有多个物理卷。
- 不同机器上面的多个物理卷对应到一个逻辑卷
- 图片写入到一个逻辑卷时会同时写入到对应的多个物理卷当中用于避免磁盘故障。
- Directory
- 维护逻辑卷到物理卷的映射关系
- 维护应用元数据
- 维护逻辑卷的空闲空间
- 维护图片对应的逻辑卷
- cache
- 缓存服务
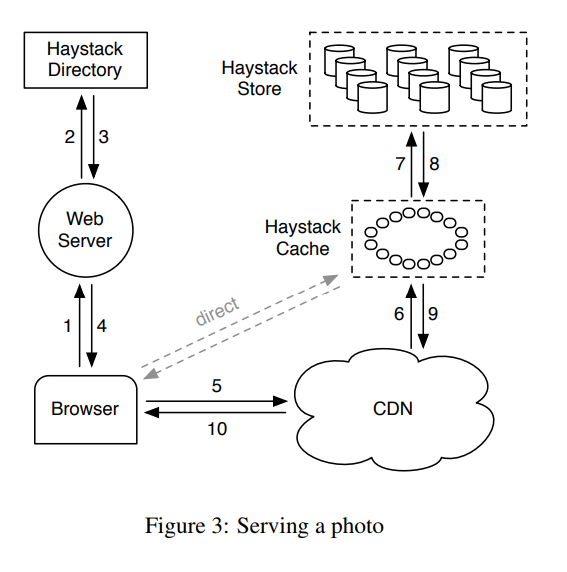
当用户访问页面图片时 web server 使用 Directory 构造一个图片 url
一个典型的url http://<CDN>/<Cache>/<Machine id>/<Logical volume, Photo>
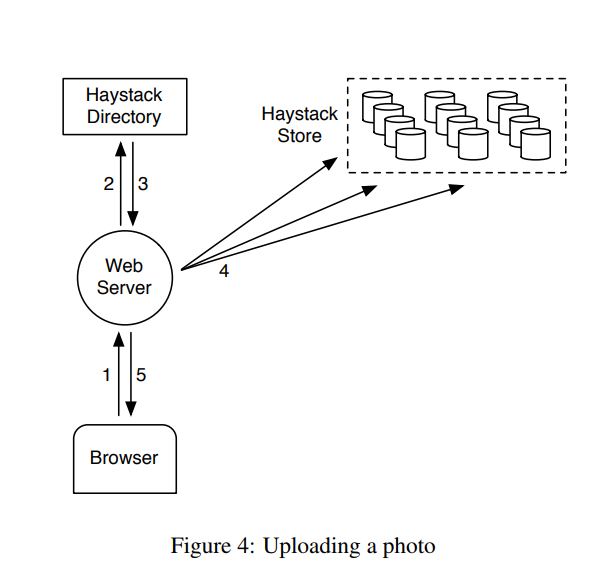
上传流程
- 浏览器对webserver 发起请求
- webserver请求 diectory
- diectory 返回一个可写的逻辑卷
- webserver为图片分配一个唯一的ID, 上传图片到逻辑卷背后对应的每个物理卷
Directory
主要提供四个功能
- 提供逻辑卷到物理卷的映射
- 为 读请求分配的逻辑卷 和 读请求分配的物理卷 提供负载均衡
- 决定一个请求应该被发送到CDN还是cache
- 标注哪些卷是只读的,为了方便这里只提供机器维度的。
新添加的机器应该是可写的,可写的机器会收到upload请求,随之时间的流逝,机器的容量会不断的减小,当容量写满时会被标记为只读。
directory将应用元数据存储在一个数据库,通接口进行访问
当一个store机器故障时,directory在应用元数据中删除对应的项,新机器上线后会接替此项。
- TIPS: 借助了外部数据库去保存应用的元数据, 可以猜测可能保存了如下元数据。
- 机器-物理卷 映射
- 逻辑卷-物理卷 映射
- 逻辑卷是否可写
- 机器是否下线
- cookie
- 图片id 到 逻辑卷的映射
- etc…
Cache
cache从CDN或者用户侧接收请求,本质上是一个DHT。
- 缓存内容
- 直接来自用户侧的请求
- 图片存在于一个可写的Store节点(刚刚上传的图片通常会在一段时间内被频繁访问)
Store
存储数据的节点,通过id cookie lvm machine 等信息可以直接返回图片。
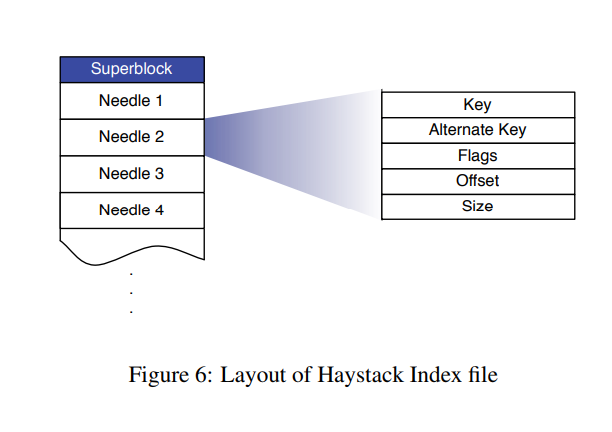
每个Store 管理多个物理卷,每个物理卷存在一个超级块结构如下图。通过逻辑卷id 在内存中查找对应的元数据,通过文件的offset操作既可定位到超级块中的图片位置并返回。
每个文件称之为一个needle结构如下
needle
- Header Magic Number 主要用作标记文件开始
- Cookie 与客户端请求携带的cookie做对比,防止图片url暴力猜解(cookie为上传时生成不可更改)
- Key 图片id 64 bit
- Alternate key 32 bit 图片规格
- Flags 标记是否删除
- Size 标记文件实体大小
- Footer Magic Number 标记图片文件结束用来恢复使用
- Data checksum 用来校验Data 是否正确
- Padding 对齐
图片读取
- cache 请求 sotre
- store 解析url 获取 lvm_id,key,alternate_key,cookie
- 找到lvm 对应的物理卷
- 根据 lvm_id,key,alternate_key 查找内存中的元数据
- 通过根据元数据中的超级块, offset找到对应图片的起始位置
- 获取cookie 并比较cookie
- 成功则返回data
- 失败则返回错误
图片写入
- web 服务器请求 Directory 获得可写lvm,
- web服务器生成key, alternate key , cookie, 同步写入对应的store节点
- sotre 节点生成对应的needle 并append到文件的末尾
- 更新store的元数据
TIPS: 原文中没有描述何时更新directory的应用元数据,个人猜测是写入成功后由webserver 发起通知directory创建对应的应用元数据。
图片删除
- 将内存中的flag与文件中的flag都设置为删除
索引文件
- 作用 快速通过索引文件恢复内存中的映射而非读取完整的超级块去恢复,有效减少store server 重启时间
- 设计
- 存储结构如下图
- 索引文件写入
- 异步写
- 问题: 有些写入的needle没有对应的索引无法通过索引恢
- 解决: 从索引文件最后一个被索引的文件,开始读取超级块进行恢复
- 异步写

文件系统
- 使用xfs
- blockmap 小可以缓存到内存中
- 支持extent 预分配存储块,防止不连续块增加io次数
- 使用xfs
故障恢复
- 后台定时检查,有问题人工介入
优化
- 压缩 定期清理标记删除的照片通常是从头读到尾丢弃已经删除的文件,并将新的照片写入一个新的超级块中
- 节省内存:
- 去掉falg 使用size 0 标记删除
- 批量上传
对比
- key 64 bit + 4 * 32bit alternate key + size 4 * 16bit = 32Byte
评测
照片请求特征
- 98%的照片请求发生在feed和相册,2天内请求多,随后降低。
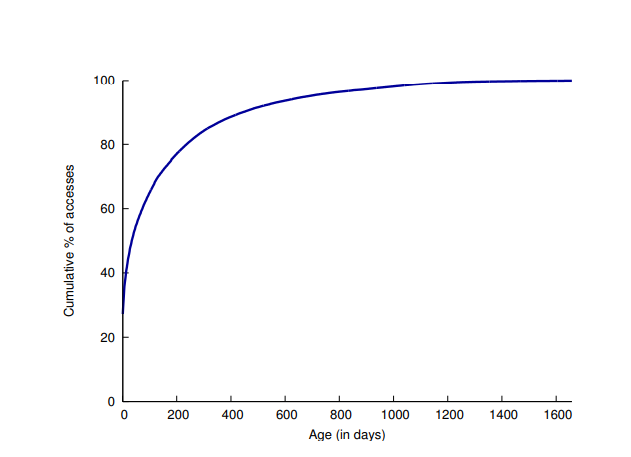
- 小图的请求比例高,原因是feed流和相册的列表均展示的是缩略图,用来降低延时,下图展示了4种尺寸的图片的请求数量和比例
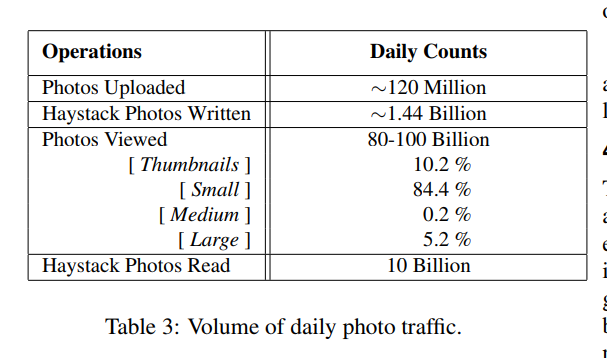
- 98%的照片请求发生在feed和相册,2天内请求多,随后降低。
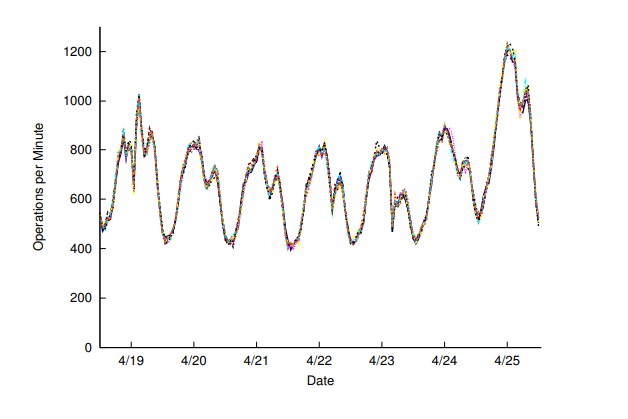
Haystack Directory 通过简单的hash策略有效的负载了服务,如下图所示,400-600个请求每分钟
Haystack Store
- 实验装置
- 硬件
- 2 hyper-threaded quad-core Intel Xeon
- 硬件
- 实验装置
CPUs
* 48 GB memory
* 12 x 1TB SATA drives raid6 关闭磁盘缓存
* Benchmark
* 工具 Haystress 自研工具发送http请求接口
* 结果如下图所示:
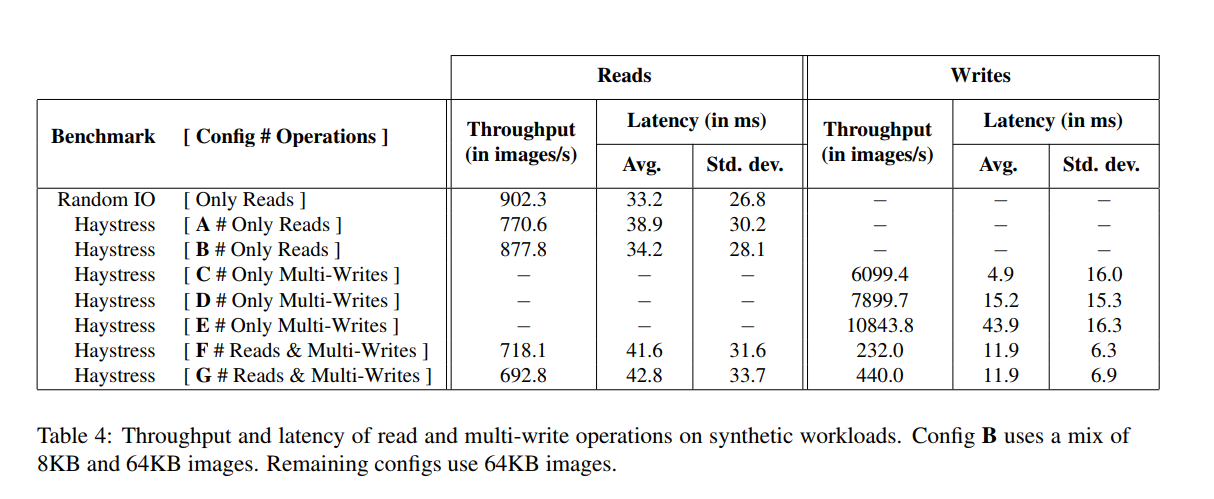
* A(读取64K) 用例吞吐量达到了原始存取的85%吞吐,延时只增加了17%
* B(读取70% 8K 30% 64K)
* 其他的均为64K
* 负载
* 考察一组机器的负载,配置相同,一部分可写可读,一部分只读。如下图所示
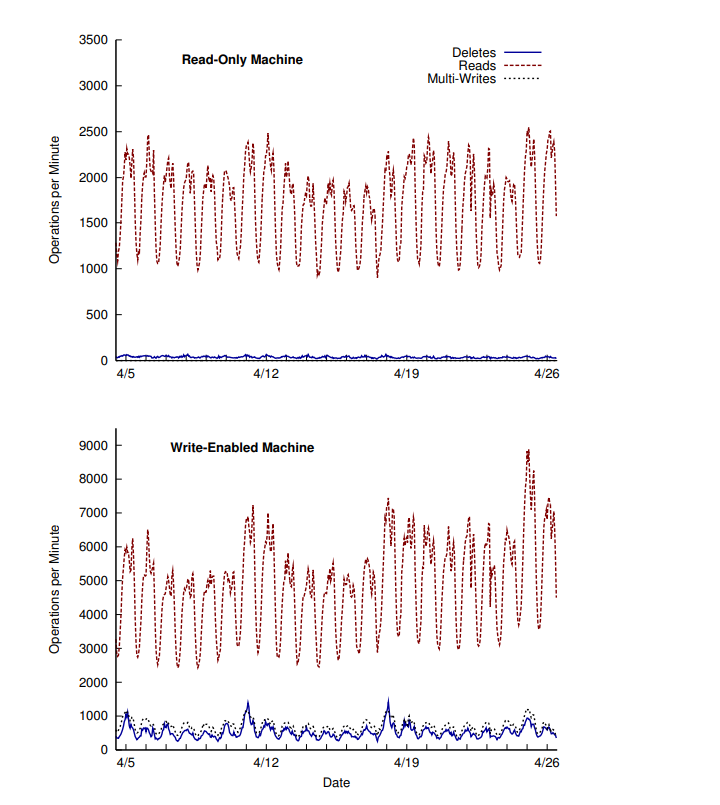
* 周日与周一是上传文件的高峰
* 线上环境一般会开启多个writter
* 可写的服务器,删除的操作也很多
* 当一个可写的服务写入越来越多的图片后获取图片的请求比例随之增加,但请求的延时并没有显著的增加如下图所示
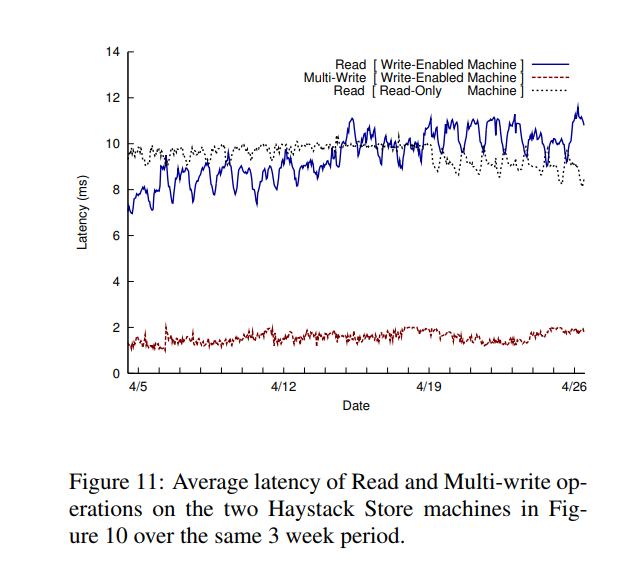
* 多个writter写入非常平稳,尽管当写入流量非常大的时候,主要原因raid控制器提供了buffer作为缓冲。
* 可写的节点主要受三部分因素影响
* 照片数的增长读流量的增长
* 缓存通常可写的store内的文件会被cache缓存
* 可写的机器写入的文件通常会被立刻读取
* 存储节点的cpu负载较低空闲时间为92%~96%
- 相关工作
- 文件系统
- 文件系统方面参考了 log-structured 文件系统,通过日志提高吞吐,通过缓存来解决读的性能。
- 对象存储
- 参考了一类对象存储的设计基于用户态构建了对象存储
- 元数据管理
- haystack并没有像ceph那样通过算法计算获得数据间的映射,而是显示的保存了映射关系,也没有像某些系统将元数据信息保存在object id 中,相反facebook认为对应关系是社交元数据中的一部分应当被管理。
- 文件系统
个人总结
到处存在的元数据
早期实现的方案中, 元数据分散在各个文件当中,并且是无用的,每次请求图片的时候都要,读入内存,面对海量图片的场景性能有巨大的影响。
N 合 1
为了减少无效IO(比如目录项的元数据,比如文件的权限信息),将零散的小文件拼接成一个大文件维护少量的元数据(id offset size cookie 等),有效减少io,并且元数据可以缓存在内存中,减少了大量无效IO。
快速恢复
haystack 的元数据是保存在内存中的,当系统崩溃,当然可以直接从超级块中恢复索引,但是由于文件特别大遍历所有文件需要大量IO并且时间缓慢,hasytack 写对象的时候会异步的写索引文件,系统发生崩溃时会从索引快速恢复,并且从索引随后一个文件的offset遍历超级快进行孤儿对象恢复。
文件系统优化
使用 extent 技术预分配存存储空间保证文件布局在物理介质上连续,减少随机io影响。