mit 6.824 学习笔记 (二) GFS 设计 (附脑图)
0x00 序
抗击懒癌过程中节节败退,但是好歹是动手开始写了。反反复复看了几遍,网上的总结也都烂大街了,这篇当做流水账吧,简述了一下组件,然后剩下的看脑图吧。
本篇是mit6.824要读的第二篇文章,原文发表于2003年的SOSP上。GFS 是 Google使用的存储系统,由大量廉价计算机构成。主要用于大文件存储。工作主要负载为追加操作。通过面向异常的思维设计了整个系统,保障了系统的可靠性。中心化的master设计有效的简化了系统设计。
0x01 设计
系统的设计必然会考虑当前的需求,以及未来的需求。下面介绍Google面临的挑战与对未来的一些设想。
背景
GFS 的产生背景是 Google 数据量的持续增长下产生的总体特征如下
- 由大量廉价计算机组成,机器故障是常态,系统自我监控和探测故障, 系统能够容忍故障, 系统能够从故障快速恢复。
- 大文件为主 (几百MB~GB级),文件数量不多(百万级),支持小文件但不需要优化,主要读负载是流式读取(大部分读取1M以上),小部读分负载是随机读取, 主要写负载是追加写,支持随机写(不提供优化),支持并发写。
- 性能主要考量是吞吐而不是延时
接口
GFS没有实现标准的posix API但是支持文件目录并支持如下操作,之所以不实现posix的原因是,兼容posix语义非常复杂,并且posix语义也并不适合 GFS 所需要支撑的上层应用。
- create
- open
- write
- read
- close
- delete
- append
- snapshot
架构
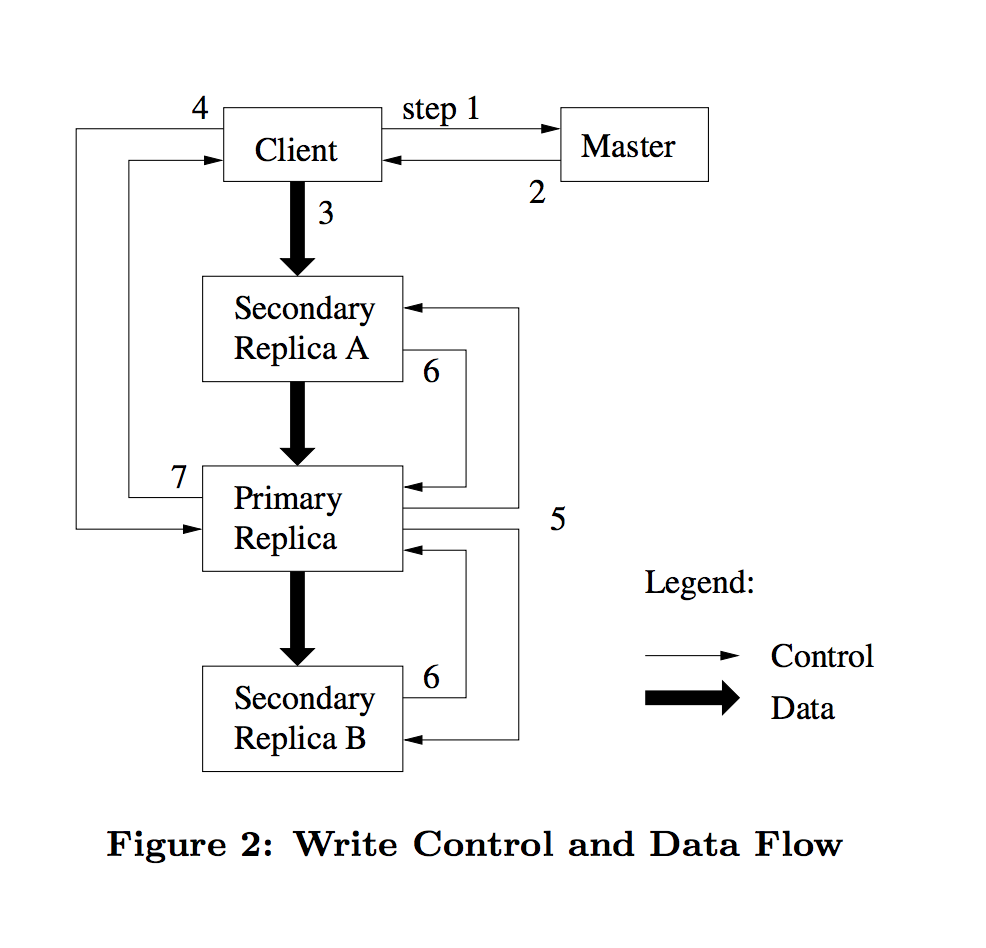
整体架构图如下所示:GFS集群是由单个Master与多个ChunkServer构成。
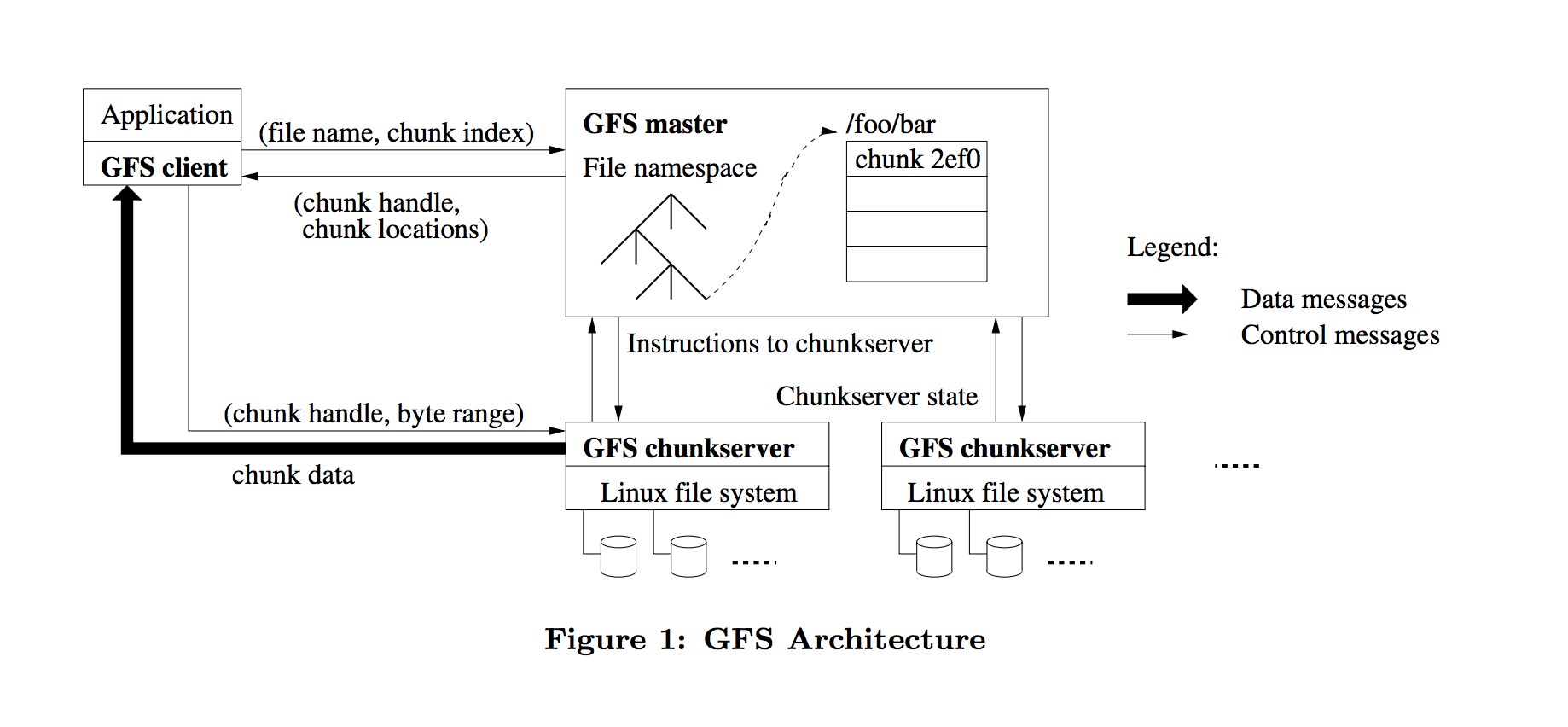
ChunkServer
- GFS在存储文件时会将文件拆分为固定大小的分块我们称之为chunk。
- 每个chunk有master分配64位全局不可变标识。
- 每个chunk会有多个副本,我们称之为replica。
- 每个replica会以Linux文件的形式存储在ChunkServer的本地磁盘上。
master作用
- 元数据管理
- 命名空间
- 访问控制信息
- 文件与Chunk的映射关系
- Chunk的位置信息
- 租约管理
- 孤儿chunk回收(不属于任何文件的chunk,删除文件产生)
- chunk迁移
- 维护与ChunkServer之间的心跳
- 下发获取任务信息
数据交互
GFS上层应用通过客户端与master进行交互与ChunkServer进行数据读写。因为主要面对的是大文件系统,所以缓存很难起到作用,GFS并没有维护客户端缓存数据信息。但是为了减少与master会维护元数据的缓存。
一次典型的读取操作流程
- 客户端指定要读取的文件名及offset
- 客户端将文件名及offset转换为对应chunk的索引号
- 客户端向master发送请求,请求内容包括文件名及chunk索引号
- master返回chunk的句柄,及chunk的位置信息
- 客户端将master使用 “文件-chunk索引号” 作为key将master的返回信息作为value进行缓存。
- 客户端向其中一个副本发起请求(通常选择最近的)
- 主副本回复客户端结果,如果发生错误了,客户端会处理错误,重新重试3-7步直到成功。此时数据会处于不一致的状态